For makers and artists relying on AI to build tools, the latest Salesforce CodeGen tutorial moves beyond simple autocomplete. It demonstrates how to construct a rigorous pipeline that generates Python code from natural language, validates it against syntax and safety rules, and reranks multiple candidates using unit tests. This approach ensures that generated artifacts are not just plausible text, but functional, secure, and testable software ready for integration.
Setting up the Salesforce CodeGen environment
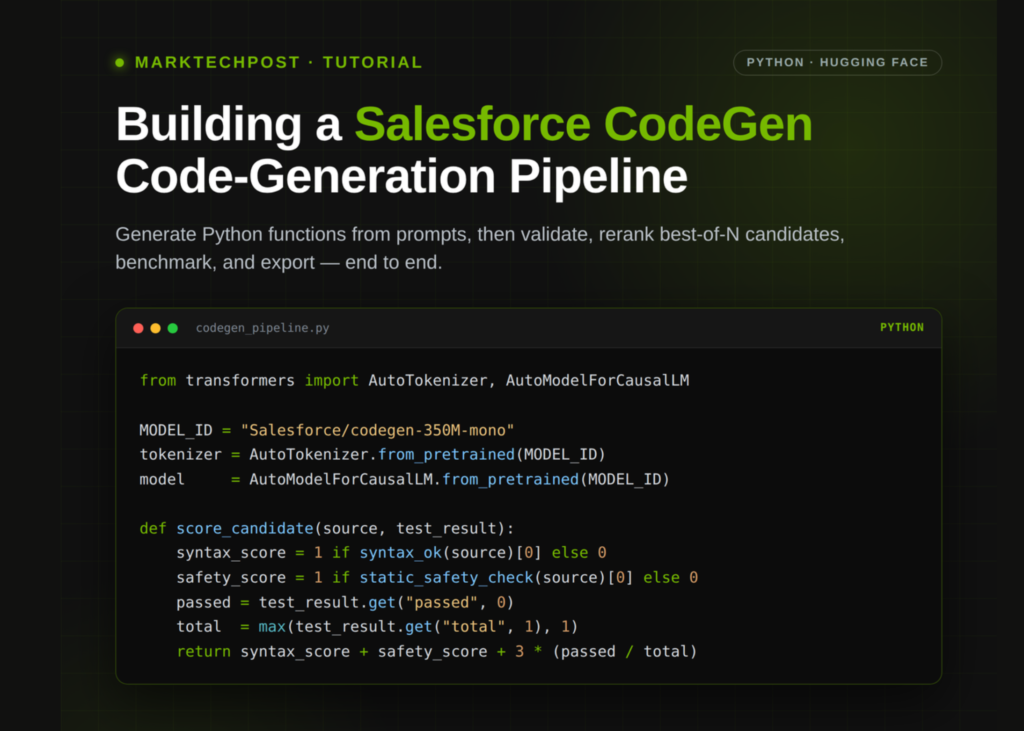
The process begins by loading the Salesforce CodeGen model directly from Hugging Face. The setup requires installing dependencies such as transformers, torch, and radon to handle complexity metrics. Once the environment is prepared, the script detects available hardware, checking for GPU acceleration to optimise inference speed and memory usage.
Users can select from several model variants, ranging from the compact codegen-350M-mono to the more capable codegen25-7b-mono_P. The system automatically configures the tokenizer and model weights, handling specific requirements like trust_remote_code for newer architectures. Helper functions are defined to manage text generation parameters—such as temperature and top-p sampling—and to render the resulting code blocks for review.
Enforcing safety and validation logic
The core of the workflow involves extracting the generated code and subjecting it to strict scrutiny before execution. A regex-based extractor isolates the specific function defined in the prompt, stripping away any surrounding conversational text or multiple code blocks.
Syntax validation occurs immediately after extraction using Python’s ast module. If the raw output contains errors, the system attempts to identify and fix them iteratively. Beyond syntax, a static safety check scans the Abstract Syntax Tree (AST) to block dangerous constructs. This includes forbidding calls to eval, exec, compile, and open, as well as preventing the use of global or non-local variables which could lead to unpredictable behaviour.
Furthermore, the pipeline restricts the set of allowed built-in functions, permitting only safe utilities like len, sum, sorted, and mathematical operators. Any attempt to call a forbidden function or access restricted attributes results in an immediate rejection of the candidate.
Validating functionality through unit tests
Static checks are only the first line of defence. The next phase involves dynamic validation using a multi-process worker to run unit tests safely. Tests are provided as a list of arguments, keyword arguments, and expected outputs.
To prevent the generated code from crashing the host environment, the execution context is sandboxed. The worker runs in a separate process with a restricted dictionary of built-ins, ensuring that even if the code attempts to import modules or access system resources, it remains contained. The system tracks pass rates and details of failures, allowing the main pipeline to weigh the quality of each candidate.
Reranking and benchmarking candidates
Since LLMs often produce multiple variations of a solution, the tutorial implements a reranking strategy. Each candidate is scored based on a composite metric: syntax validity, safety compliance, test pass rate, and code complexity.
The complexity metric, calculated via the radon library, penalises overly convoluted logic. The final score combines these factors to identify the most robust implementation. This structured evaluation transforms the model from a generative text engine into a reliable code synthesis tool capable of delivering production-ready snippets.
Key takeaways
Generative AI for code requires more than inference; it demands a pipeline that extracts, sanitises, and validates output against strict safety and syntax rules.
Static analysis using the AST module can effectively block dangerous functions like
evalandexecbefore the code ever runs.Multi-process execution with sandboxed environments allows for safe unit testing of generated code without risking system stability.
Combining test pass rates with complexity metrics enables intelligent reranking of multiple generated solutions to find the optimal code.
Stay ahead of AI. Get the most important stories delivered to your inbox — no spam, no noise.


