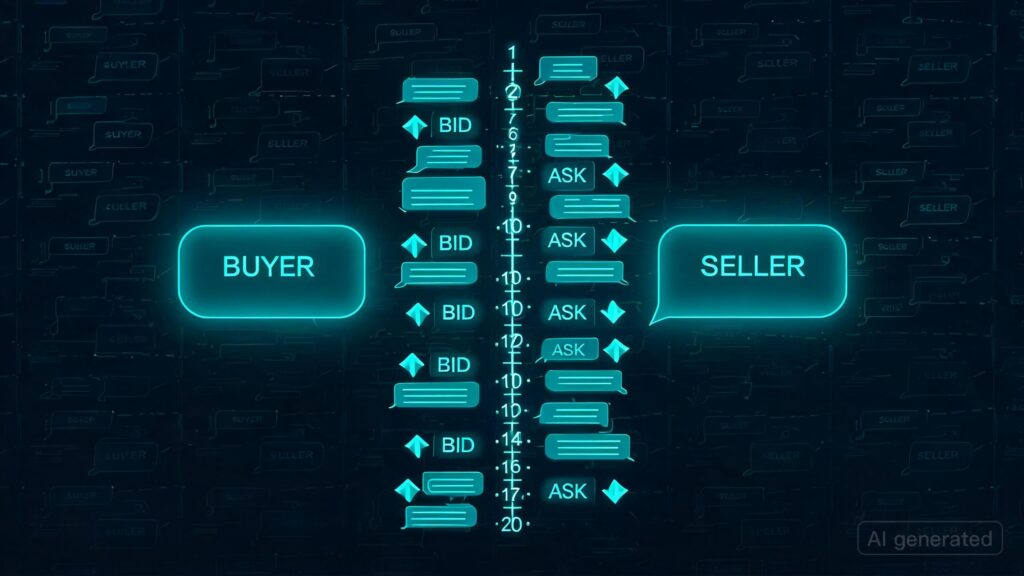
**PACT, head-to-head LLM negotiation benchmark. 20-round buyer-seller bargaining game:** Thousands of matchups test AI models in a simulated negotiation environment where each round involves messaging and submitting bids/asks. This initiative aims to assess the strategic capabilities of large language models like GPT-5.5, Opus 4.7, DeepSeek V4 Pro, Gemini 3.1 Pro, and Kimi K2.6 through repeated rounds of interaction focused on persuasion, commitment, deception, anchoring, threats, and adaptation.
**Takeaways:**
– The PACT benchmark provides a robust test suite for evaluating AI negotiation strategies across multiple models.
– It highlights the diverse strengths and weaknesses of different LLMs in simulated economic interactions.
– The results offer insights into how these models might perform in real-world applications where trust and strategic maneuvering are crucial.