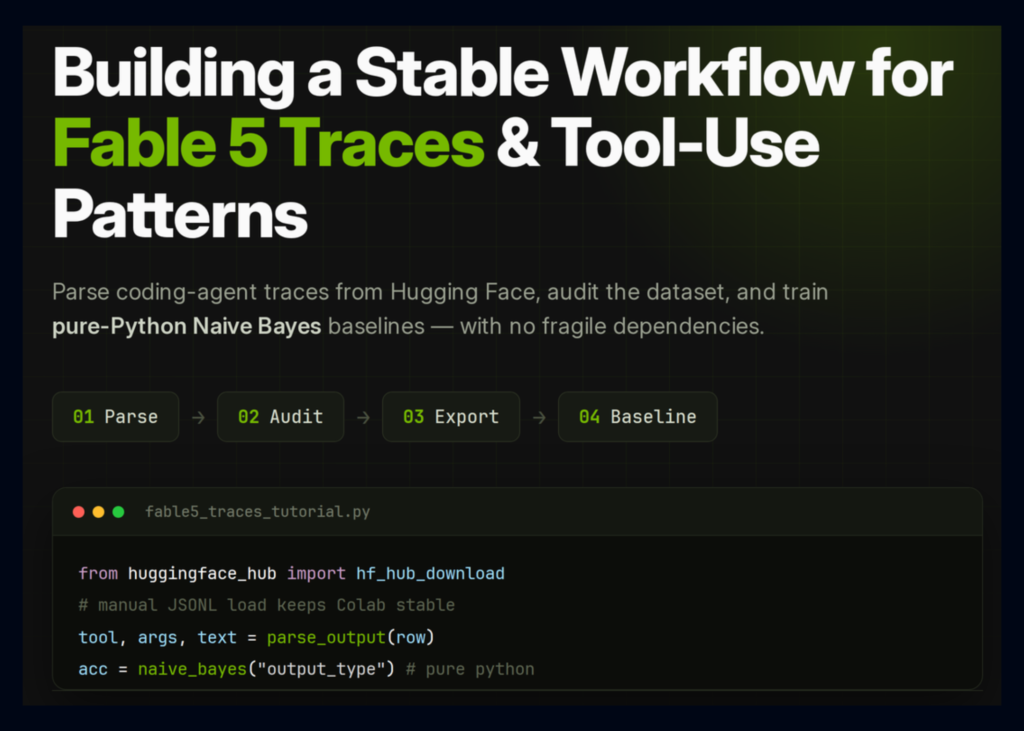
A new Colab tutorial details how to build a stable workflow for the Fable 5 Traces dataset. The guide avoids heavy dependencies like scikit-learn and scipy. Instead, it manually downloads and parses the merged JSONL file to ensure the notebook runs without errors.
Setting Up the Colab Environment and Helpers
The setup section defines a lightweight environment with only the necessary packages. It installs huggingface_hub, rich, and tqdm. The code sets the dataset ID to Glint-Research/Fable-5-traces and creates an output directory at /content/fable5_traces_tutorial_outputs.
Key configuration variables include a random seed of 42 and a limit of 900 characters for text previews. The script also defines patterns to detect secrets, such as API keys and tokens, to prevent accidental leakage during analysis.
Dataset: Glint-Research/Fable-5-traces
Output directory: /content/fable5_traces_tutorial_outputs
Manual JSONL loading: True
CoT research export enabled: False
Parsing Utilities for Tool Calls and Text Outputs
The tutorial provides functions to handle different data formats. It attempts to parse JSON strings that look like objects or arrays but fall back to the original string if the format is invalid.
Extracting tool names requires checking multiple possible keys in the output dictionary. The code looks for direct keys like name or tool_name. If those are missing, it checks nested structures under tool_call or function_call.
Arg extraction follows a similar logic. It scans for keys such as input or arguments. If the data is nested, it drills down into those sections to find the parameters.
Text payloads are handled by checking for specific keys like text or content. If the value is a list or dictionary, it converts the structure into a safe JSON string before returning it.
Auditing Data and Visualising Distributions
The workflow inspects repository files and previews raw trace examples. It normalises tool calls and text outputs to ensure consistency across the dataset.
Security checks scan for potential secret-like patterns. The script redacts any matches with a placeholder string before displaying results.
Visualisation tools plot key distributions. These charts show output types, tools used, source roots, and text lengths. The code also exports safe chat datasets without Chain of Thought reasoning for supervised fine-tuning.
Finally, the guide trains pure-Python Naive Bayes baselines. This step assesses whether trace context can predict the assistant’s output type and tool usage.
What it means
Developers can now run this analysis in Colab without installing heavy machine learning libraries. The manual parsing approach keeps the environment stable and reproducible.