

“`html
Validating agentic behavior when “correct” isn’t deterministic
Modern software testing is built on a fragile assumption: correct behavior is repeatable. For deterministic code, that assumption mostly holds. But for autonomous agents like Github Copilot Coding Agent (aka Agent Mode), especially as we explore the frontiers of integrated “Computer Use,” that assumption breaks down almost immediately.
The challenges of agent-driven validation
Imagine you’re responsible for a GitHub Actions pipeline that relies on Copilot Agent Mode to validate real-world workflows. The agent could be leveraging Computer Use, navigating within a containerized cloud environment, for the workflow validation.
On Tuesday, the build is green. On Wednesday, the test fails-even though no code has changed.
Here’s what happened: A minor network lag on the hosted runner caused a loading screen to persist for a few extra seconds. The agent waited, adapted, and successfully completed the tasks correctly. But your CI pipeline still flagged the run as a failure-not because the task failed, but because the execution path no longer matched the recorded script or assertion timing.
The agent didn’t fail. The validation did.
This surfaces three recurring pain points that create a “trust gap” in agent-driven testing:
- False negatives: The task succeeded, but the test still failed due to variability not accounted for.
- Fragile infrastructure: Tests fail due to timing or environmental noise unrelated to correctness.
- The compliance trap: The outcome may be correct, but a regression is flagged because the agent’s behavior diverges from what the automated test expected.
We’re in a transition period where agentic systems like Github Copilot Coding Agent are enabling faster development, but our traditional validation approaches remain rigid. In deterministic software, correctness is as simple as matching a specific input to a known output. But with agents, the process in between is intentionally non-deterministic. As agents are increasingly deployed in production, correctness isn’t about following a prescribed set of steps-it’s about “reliably achieving the essential outcomes.”
To scale these systems, we need a validation framework that can distinguish between “incidental noise” (like a loading screen) and “critical failures.” Correctness shifts from “did this happen?” to “what had to happen for success to be real?”
Why existing testing approaches break down for autonomous agents
Traditional testing tools work well when execution paths are fixed. They struggle when behavior branches-these tools begin to fracture, not because they’re poorly engineered, but because they assume a stable sequence.
When we apply these to a Copilot Coding Agent, including when navigating a containerized environment, the limitations become clear across four common paradigms:
- Assertion-based testing: Requires manual, labor-intensive specifications for every check and fails to account for valid alternative execution paths.
- Record-and-replay tools: Highly sensitive to environmental noise; minor rendering differences or timing variations often trigger false failures.
- Visual regression testing: Compares screenshots in isolation without understanding the broader execution flow or semantic meaning.
- ML oracles: These “black boxes” require thousands of training examples and offer no explainability when they flag a behavior as incorrect.
While these approaches differ in implementation, they share a common structural assumption: Correctness is defined by adherence to a particular sequence of observable states. For agentic systems, that assumption breaks down. To build true developer trust in these systems, including Github Copilot, we must move beyond checking linear scripts and start validating structured behaviors.
Reframing correctness: Essential vs. optional behavior
To move past brittle tests and build the Trust Layer, we have to fundamentally change how we define “correct.” In agentic systems, correct executions don’t have to look identical; they do need to share a common logical structure.
The conceptual shift
Think of a computer use-enabled Github Copilot Coding Agent performing a search in VS Code in a containerized cloud environment. In one run, a loading screen appears for several seconds; in another, the UI loads instantly (shown below).
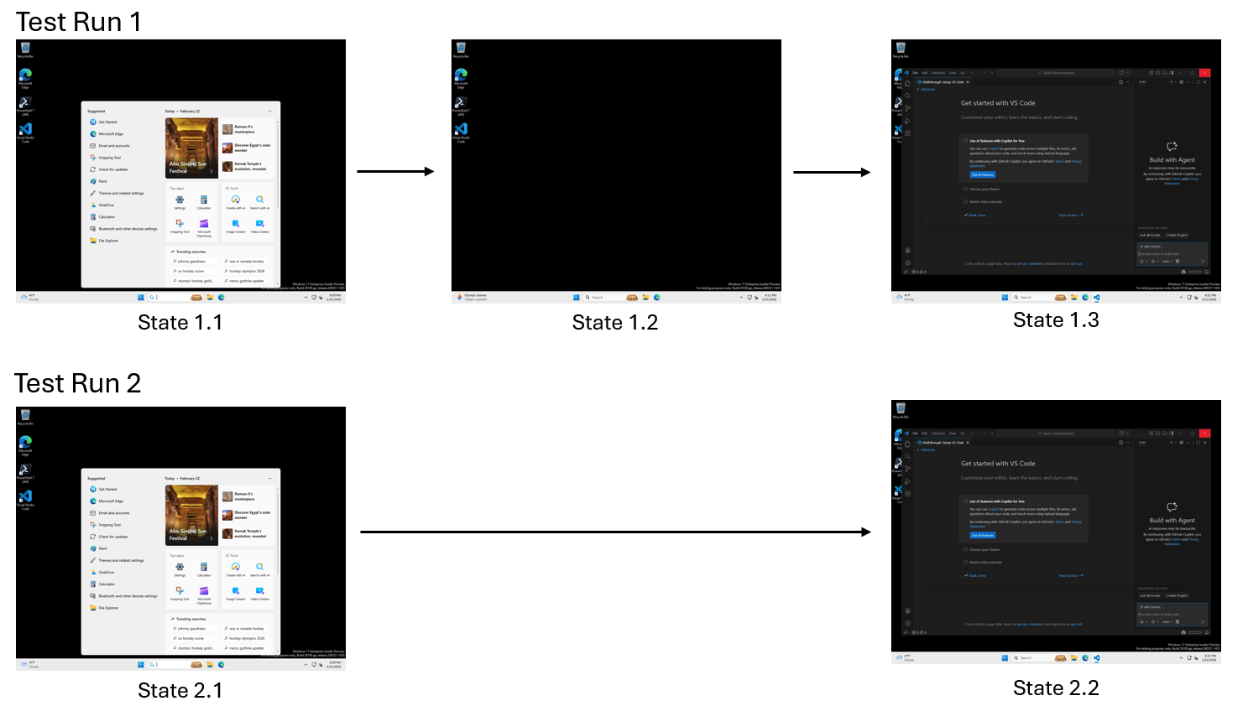
A traditional test sees these as two different results. But to a developer, the loading screen is incidental; it doesn’t change whether the task was successful.
We can classify agent behavior into three categories:
- Essential states: Milestones that must occur for success to be real, such as reaching the “Search Results” screen.
- Optional variations: Incidental states like loading spinners or decorative UI changes that vary based on environment.
- Convergent paths: Different sequences of steps (like using a hotkey vs. a menu) that ultimately rejoin at the same outcome.
A loading screen may appear or not. But search results must appear. Only one of these determines correctness.
From intuition to theory: Dominator analysis
The distinction between “must-have” and “incidental” behaviors is a concept rooted in compiler theory known as dominator relationships. In a control-flow graph, a node A “dominates” node B if every path from the start to B must go through A.
By applying dominator analysis to agent execution traces, we can automatically identify:
- Which states are mandatory
- Which states are optional
- Where different paths converge
This lets us extract a minimal, explainable definition of correctness.
Modeling executions as graphs, not scripts
To capture the complexity of agentic behavior, we must move away from treating executions as linear, one-dimensional scripts. Instead, our framework models behavior using a graph-based structure known as a PREFIX TREE ACCEPTOR (PTA).
From linear traces to structured graphs
In this model, an execution is not a series of commands but a directed graph where:
- Nodes represent observable states, such as screenshots for UI agents or code snapshots for development agents.
- Edges represent transitions, capturing the actions (clicks, keystrokes, or API calls) taken to move between states.
This lets us represent branching and convergence-concepts that are impossible to capture in a linear script. By shifting the representation from a sequence of steps to a structured behavior model, we stop penalizing agents for taking a different path and start validating whether they followed a logically sound one.
How we solve it: A structural approach to correctness
To move agents from experimental demos to production-grade infrastructure, our team developed a novel validation algorithm that moves away from rigid scripts and instead learns by example. To test this, we focused on a complex non-deterministic environment: an AI agent navigating Visual Studio Code via “Computer Use.” By observing just 2–10 successful sessions, our algorithm automatically constructs a “ground truth” model that distinguishes between an agent’s valid variations and actual failures.
The workflow: From traces to a “master” graph
- Capture (PTA Construction): We collected 2–10 successful execution traces and converted them into PREFIX TREE ACCEPTORS (PTAs), directed graphs where nodes represent observable UI states and edges represent actions.
- Generalize (Semantic Merging): Our algorithm merged these traces into a unified graph. It employed a three-tiered equivalence detection framework-combining fast visual metrics with LLM semantic analysis-to decide if two states are logically equivalent, such as ignoring a timestamp change while flagging a missing UI control.
- Extract the Skeleton (Dominator Analysis): We applied dominator analysis to the merged graph to identify “essential states,” milestones every successful run must pass through-while automatically filtering out “optional” states like loading spinners.
This approach is uniquely powerful for developers because it requires no manual specification. Instead, it learns from examples and can scale to new environments and tasks without additional training data.
Key Takeaways
- Shift focus from linear scripts to structured behavior models.
- Use graphs for better representation of branching and convergence.
- Leverage example-based learning rather than rigid rules.


