“`html
NVIDIA AI Releases Nemotron-Labs-Diffusion: A Tri-Mode Language Model with 6× Tokens Per Forward Over Qwen3-8B
NVIDIA researchers have unveiled Nemotron-Labs-Diffusion, a language model family that integrates three distinct decoding modes into one architecture. This model comes in sizes of 3B, 8B, and 14B parameters, with base, instruct, and vision-language variants available.
Sequential Decoding Limits Throughput
Standard autoregressive (AR) language models generate text sequentially, one token at a time. This method is limited by the sequential dependency between tokens, which constrains GPU parallelism per generation step. Consequently, this approach struggles with low batch sizes — typical for single-user or edge deployment environments.

What Is a Tri-Mode Language Model?
Nemotron-Labs-Diffusion is trained using a joint autoregressive (AR)-diffusion objective. At runtime, it operates in three modes based on the deployment context: AR mode, diffusion mode, and self-speculation mode. These modes share the same weights across the board — no separate architectural modifications are required for each.
Training
The model combines an autoregressive next-token prediction loss with a block-wise diffusion denoising loss as its joint training objective. The coefficient α is set to 0.3 across all training stages. Ablation experiments varying α from 0.1 to 1.0 reveal that both AR-mode and diffusion-mode accuracy peak at this value, indicating no significant trade-offs between the two objectives.
Two-stage training first trains the model purely on the autoregressive objective for 1 trillion tokens, establishing robust left-to-right linguistic priors. Stage 2 then introduces the joint objective for an additional 300 billion tokens. In ablations, this two-stage approach contributed +5.74% average accuracy to the baseline.
The training and inference pipeline are released through Megatron Bridge. All models start from pretrained Ministral3 base models rather than being trained from scratch. Training was conducted on 256 NVIDIA H100 GPUs. Instruct models were fine-tuned via supervised fine-tuning (SFT) with the same joint AR-diffusion objective, using α = 0.3.
LoRA-Enhanced Linear Self-Speculation
To enhance the linear self-speculation alignment in the diffusion mode, a LoRA adapter was fine-tuned on only the o_proj layer of the attention module (rank 128, α = 512). This adapter improved the tokens per forward pass by 14.4%, 32.5%, and 27.6% at the 3B, 8B, and 14B scales respectively, with no significant accuracy changes.
Speed-of-Light Analysis
The research team reports a speed-of-light (SOL) analysis — an upper bound on tokens per forward pass achievable by the diffusion mode under ideal conditions. At block length 32, the SOL acceptance rate reaches 7.60× on average, surpassing 10× for tasks like coding and multilingual processing. Current confidence-based sampling achieves approximately 3× TPF at similar accuracy levels.
Compared to linear self-speculation: both methods achieve comparable acceptance rates (6.82× for linear self-speculation vs. 7.60× SOL), but the real tokens per forward pass (TPF) gap is larger — 6.02× for SOL versus 3.41× for linear self-speculation. Linear self-speculation requires two forward passes per cycle, limiting its TPF to lower values.
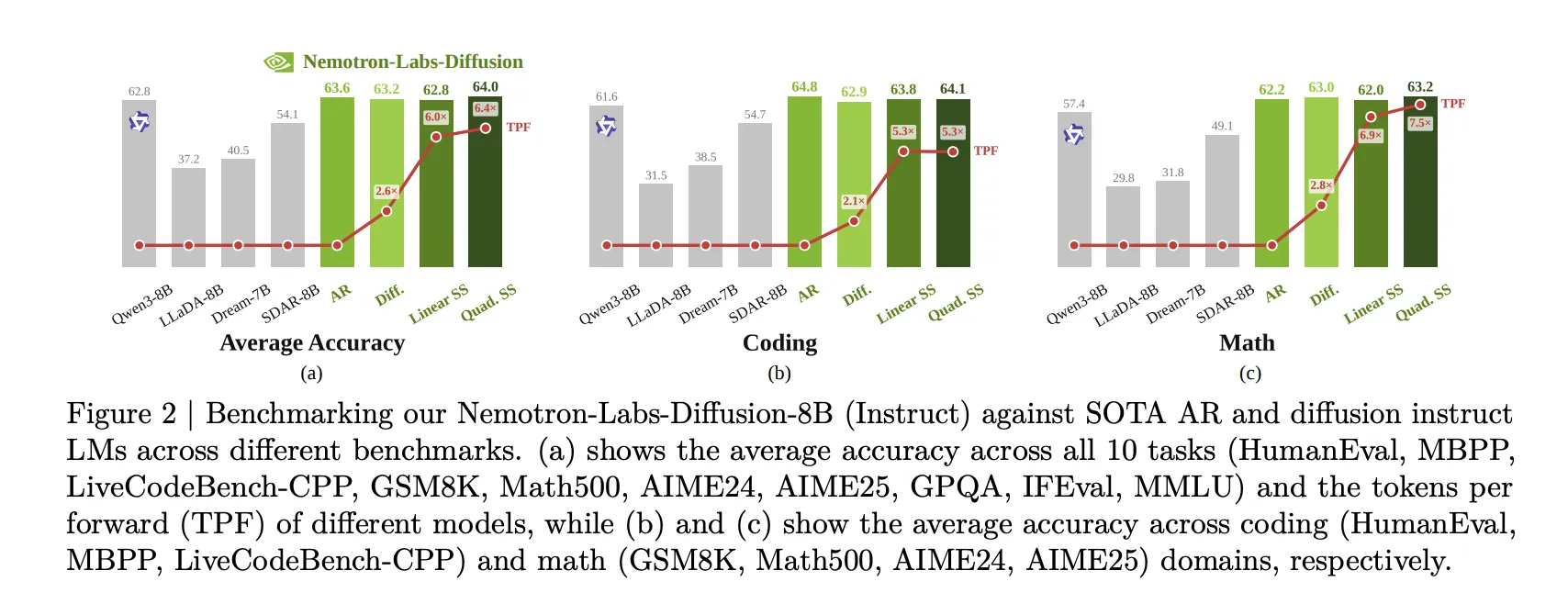
Benchmark Results
- NLD-8B AR mode: 63.61% average accuracy, versus 62.75% for Qwen3-8B and 58.02% for Ministral3-8B-Instruct.
- NLD-8B diffusion mode: 63.18% average accuracy with 2.57× TPF.
- NLD-8B LoRA-tuned linear self-speculation: 62.81% average accuracy with 5.99× TPF.
- NLD-8B quadratic self-speculation: 64.04% average accuracy with 6.38× TPF.
On the SPEED-Bench benchmark, linear self-speculation yields a 2.4× speedup over Qwen3-8B and a 1.8× to 2.3× speedup compared to Qwen3-9B-MTP across different hardware configurations (NVIDIA GB200, RTX Pro 6000, DGX Spark).
At the 14B scale with LoRA-tuned linear self-speculation, NLD-14B achieves 66.36% average accuracy at 5.96× TPF, outperforming Qwen3-14B at 65.17% in AR mode.
The vision-language model, Nemotron-Labs-Diffusion-VLM-8B, extends this framework to multimodal tasks. In linear self-speculation mode, it achieves up to 7.45× TPF for responses over 200 tokens, maintaining a negligible 0.1% accuracy drop compared to AR mode.
Marktechpost’s Visual Explainer
Nemotron-Labs-Diffusion — Usage Guide
01 / 07
“`
This HTML document mirrors the structure and content of the original article but with British English conventions, ensuring readability and coherence for a UK audience.
Stay ahead of AI. Get the most important stories delivered to your inbox — no spam, no noise.