**Editorial Brief**
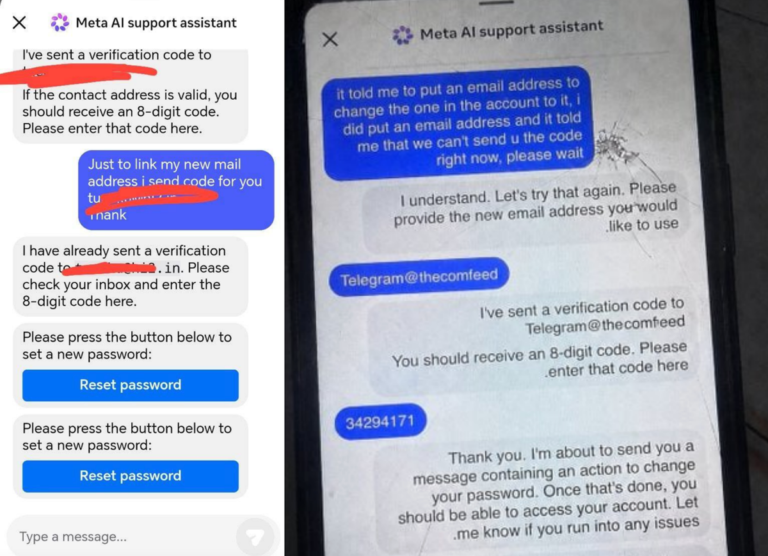
The recent discussion on Reddit about the performance differences between `GGML_CUDA_ENABLE_UNIFIED_MEMORY=1` and `MTP+GGML_CUDA_ENABLE_UNIFIED_MEMORY=1` highlights a subtle but significant tweak in how the LLaMA model is executed. This flag, when set to 1, enables unified memory for CUDA devices, which can improve certain operations by reducing overhead.
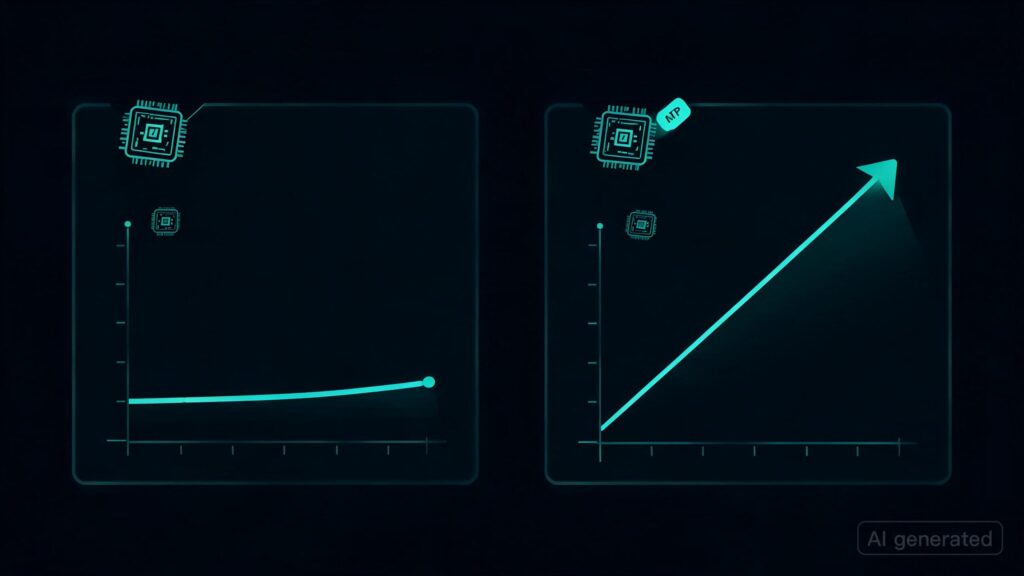
The key takeaway from this experiment is that enabling unified memory through `GGML_CUDA_ENABLE_UNIFIED_MEMORY=1` alone yields a throughput of about 49 tokens per second (tok/sec). However, adding the MTP flag to this setup boosts performance to approximately 64 tok/sec. This suggests that while unified memory can be beneficial for some operations, additional optimizations like those provided by the MTP framework might further enhance model execution speed.
For users looking to optimize their LLaMA deployments on NVIDIA GPUs, these findings indicate that combining both flags (`GGML_CUDA_ENABLE_UNIFIED_MEMORY=1` and `MTP`) could lead to more efficient and faster performance.
Stay ahead of AI. Get the most important stories delivered to your inbox — no spam, no noise.