
Liquid AI has released LFM2.5-230M, its smallest model to date, designed specifically for running agentic tasks on phones, robots, and other edge hardware. Both the base and instruction-tuned checkpoints are open-weight and available on Hugging Face.
The scope is intentionally narrow. This is not a general reasoning engine. It is built for data extraction and tool use on limited hardware.
TL;DR
- Liquid AI’s LFM2.5-230M is its smallest model yet: 230M parameters, open-weight, built on the LFM2 architecture.
- It runs on-device at 213 tokens per second on a Galaxy S25 Ultra and 42 on a Raspberry Pi 5.
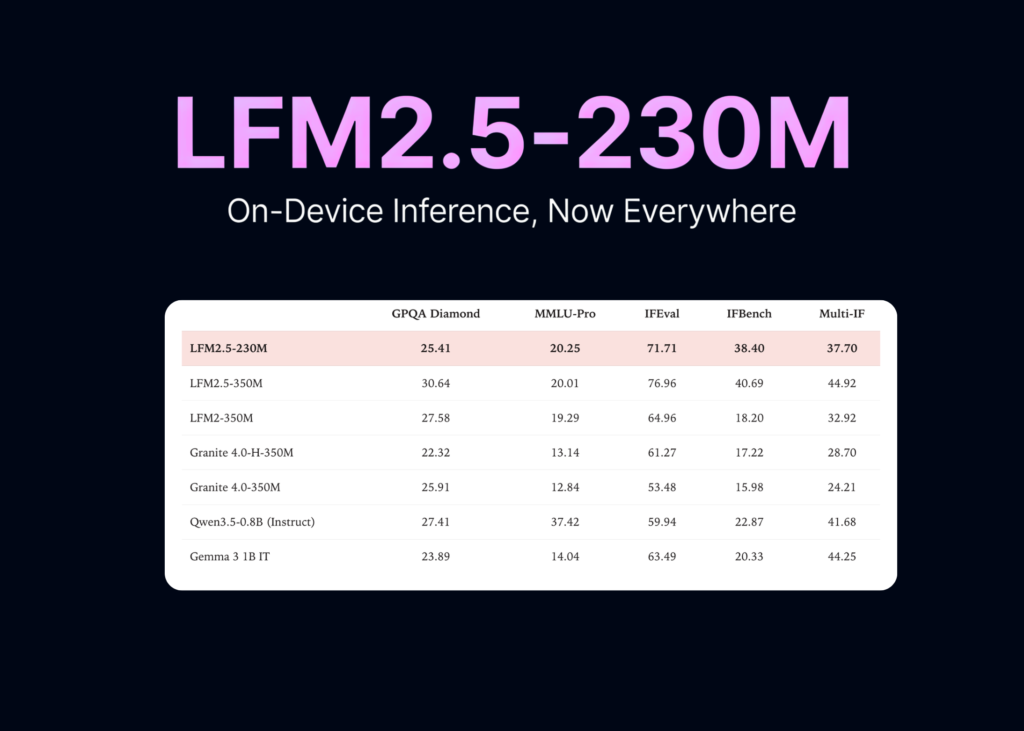
- It outperforms larger models like Qwen3.5-0.8B and Gemma 3 1B on instruction following and data extraction.
- The model is tuned for tool use and extraction; it is not intended for math, code generation, or creative writing.
- Support is available from day one across llama.cpp, MLX, vLLM, SGLang, and ONNX, with a footprint of 293–375 MB.
What is LFM2.5-230M?
LFM2.5-230M is a 230-million-parameter, text-only model built on the LFM2 architecture. It has 14 layers in total. Eight are double-gated LIV convolution blocks and the remaining six are grouped-query attention blocks. This hybrid layout targets fast CPU inference.
The context length is 32,768 tokens. The vocabulary size is 65,536. The knowledge cutoff is mid-2024. It supports ten languages, including English, Chinese, Arabic, and Japanese.
The Liquid AI team ships two checkpoints. LFM2.5-230M-Base is the pre-trained model for fine-tuning. LFM2.5-230M is the general-purpose instruction-tuned version. The license is lfm1.0.
Training and Post-Training
The model was pre-trained on 19 trillion tokens. That total includes a 32K context extension phase. The post-training recipe then runs in three stages.
First comes supervised fine-tuning with distillation from the larger LFM2.5-350M. Second is direct preference optimisation. Third is multi-domain reinforcement learning. This preserves flexibility for downstream specialisation.
The distillation step is what keeps a 230M model competitive with larger checkpoints. It inherits behaviour from the bigger LFM2.5-350M on targeted tasks.
Benchmark
The Liquid AI team evaluated LFM2.5-230M across ten benchmarks. They cover knowledge, instruction following, data extraction, and tool use.
The instruction-following results support the claim. On IFEval, LFM2.5-230M scores 71.71. That beats Qwen3.5-0.8B (59.94) and Gemma 3 1B IT (63.49). On IFBench it scores 38.40, ahead of both. On CaseReportBench, a clinical data-extraction test, it scores 22.51.
| Model | Params | IFEval | IFBench | CaseReportBench | BFCLv4 | MMLU-Pro |
|---|---|---|---|---|---|---|
| LFM2.5-230M | 230M | 71.71 | 38.40 | 22.51 | 21.03 | 20.25 |
| LFM2.5-350M | 350M | 76.96 | 40.69 | 32.45 | 21.86 | 20.01 |
| Granite 4.0-H-350M | 350M | 61.27 | 17.22 | 12.44 | 13.28 | 13.14 |
| Qwen3.5-0.8B (Instruct) | 800M | 59.94 | 22.87 | 13.83 | 18.70 | 37.42 |
| Gemma 3 1B IT | 1B | 63.49 | 20.33 | 2.28 | 7.17 | 14.04 |
LFM2.5-230M leads on instruction following and data extraction. It trails on broad knowledge: MMLU-Pro is 20.25, behind Qwen3.5-0.8B’s 37.42. It is also weak on some agentic tool use. On τ²-Bench Telecom it scores just 5.26.
Liquid AI is direct about the limits. It does not recommend the model for reasoning-heavy workloads. That means advanced math, code generation, and creative writing.
Use Cases With Examples
The model fits two jobs well.
- The first is large-scale data extraction pipelines. Picture a pipeline parsing 100,000 clinical reports into structured fields. A 4-bit build with a 293–375 MB memory footprint runs that on commodity CPUs. You extract locally, with no per-token API bill.
- The second job is lightweight on-device agentic workloads. Think a home automation hub that turns speech into tool calls. Or a phone assistant that routes a request to the right function.
As an early signal, Liquid AI deployed the model on a Unitree G1 humanoid robot. It ran entirely on the robot’s onboard NVIDIA Jetson Orin. There the model acted as a skill-selection layer. It turned one natural-language instruction into a sequence of tool calls. Those calls invoked low-level skills from NVIDIA’s SONIC framework.
Tool Use: How It Works
LFM2.5 supports function calling in four steps. You define tools as JSON in the system prompt. The model writes a Pythonic function call between special tokens. You execute the call and return the result. The model then writes a plain-text answer.
By default the call is a Python list. It sits between the <|tool_call_start|> and <|tool_call_end|> tokens. Here is the documented pattern, with the tool JSON abbreviated:
<|im_start|>system
List of tools: [{"name": "get_candidate_status",
"parameters": {"candidate_id": {"type": "string"}}}]<|im_end|>
<|im_start|>user
What is the current status of candidate ID 12345?<|im_end|>
<|im_start|>assistant
<|tool_call_start|>[get_candidate_status(candidate_id="12345")]<|tool_call_end|>Checking the current status of candidate ID 12345.<|im_end|>You can also force JSON-formatted calls through the system prompt.
Running It: A Minimal Example
The model works with Transformers 5.0.0 and up. The recommended generation settings are temperature 0.1, top_k 50, and repetition_penalty 1.05. Note the do_sample=True flag, which is required for those sampling settings to apply.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "LiquidAI/LFM2.5-230M"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
dtype="bfloat16",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
inputs = tokenizer.apply_chat_template(
[{"role": "user", "content": "What is C. elegans?"}],
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
output = model.generate(
**inputs,
do_sample=True,
temperature=0.1,
top_k=50,
repetition_penalty=1.05,
max_new_tokens=512,
)
print(tokenizer.decode(output[0][inputs["input_ids"].shape[-1]:], skip_special_tokens=True))Liquid AI also publishes fine-tuning recipes. They cover SFT, DPO, and GRPO with LoRA, via Unsloth and TRL. Each ships as a Colab notebook.
What it means
For developers building on-device applications, this model offers a practical alternative to larger, cloud-dependent systems. The 293–375 MB footprint allows it to run on standard mobile hardware without significant memory pressure. This enables local processing of sensitive data, such as medical records or personal logs, without sending information to an external server. The performance on instruction following and data extraction suggests it can handle specific automation tasks reliably, even if it cannot replace general-purpose models for complex reasoning or creative generation.


