Is it agentic enough? Benchmarking open models on your own tooling
The landscape of software development is shifting. Coding agents are no longer merely assistants; they are increasingly taking the wheel, interacting directly with our software stacks. You describe a task, and the agent selects the library, constructs the function calls, executes them, and repairs its own errors. If the existing library proves obstructive, the agent will happily bypass it and rewrite the logic from scratch.
This shift introduces a critical new requirement for library developers: code must not only be correct and performant but also architected to be effectively driven by an agent. A clunky API or outdated documentation frustrates human developers, but it now forces the agent down a longer, more expensive path.
Traditional benchmarks often focus solely on the final output. We wanted to measure the entire journey: not just whether the agent succeeded, but the computational cost involved and how that varies across models, library versions, and tasks. We measured this using
transformers
as our primary case study.
In this post, we introduce a specialized benchmark focused on the process of finding an answer. We provide a simple implementation of a harness running entirely on open models driven by the pi coding agent, with the full combination of models, revisions, and tasks executed across Hugging Face Jobs to ensure every run occurs on identical hardware.
But how exactly do you optimise software for agents?
We adhere to two core software principles:
- If it isn’t tested, it doesn’t work
- If it isn’t documented, it doesn’t exist
These tenets remain valid for agentic-optimised tooling, and for once, they are intrinsically linked.
To serve an agent, your tool must be discoverable. The API must be clear, and the documentation must be extensive. These resources need to be structured so an agent can access useful files and examples rapidly. If you want your tool to function for an agent, you must test it for agentic use.
Testing software for agentic-use
We use
transformers
as our example throughout this analysis: agents employing it to solve machine learning tasks—such as text classification, image captioning, and audio transcription—rather than contributing code to the library itself. Although the harness was designed to work with any tool operable from the command line.
Our intuition regarding
transformers
was that usage could be dramatically simplified with a few strategic changes: a Command Line Interface (CLI), a Skill, and self-contained, task-specific examples. This is the same recipe recently applied to the
hf
CLI, which was redesigned to be agent-optimised. Agents using that updated CLI consumed 1.3–1.8× fewer tokens, with some instances seeing up to a 6× reduction. We wanted to determine if this kind of efficiency gain generalises to
transformers
.
Intuition is powerful, but we required evidence before opening pull requests that would add several thousand lines of code to such a widely used codebase. We set out to measure what success actually looks like.
Not all successes are equal
Two agents might both produce the correct label for a sentiment-classification task, but their journeys differ significantly:
- One agent writes a 40-line Python script, imports
transformers
, debugs a shape error, re-runs the process twice, and finally prints the answer;
while the other
- types
transformers classify --model ... --text "..."
and completes the task in a single call.
Both reach
POSITIVE (0.9999)
, yet here are the two distinct paths an agent took on this exact task:
# Task: classify the sentiment of "I absolutely loved the movie, it was fantastic!" - # one agent: pipe a script into python and parse the output - python - <<'PY' - from transformers import AutoTokenizer, AutoModelForSequenceClassification - import torch - import torch.nn.functional as F - - model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased-finetuned-sst-2-english") - tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased-finetuned-sst-2-english") - inputs = tokenizer("I absolutely loved the movie, it was fantastic!", return_tensors="pt") - with torch.no_grad(): - logits = model(**inputs).logits - probs = F.softmax(logits, dim=1) - idx = torch.argmax(probs, dim=1).item() - print(model.config.id2label[idx], probs[0][idx].item()) - PY + # the other agent: one command + transformers classify \ + --model distilbert/distilbert-base-uncased-finetuned-sst-2-english \ + --text "I absolutely loved the movie, it was fantastic!"
Both methods reach the same result. However, they have very different profiles regarding cost, latency, token usage, and failure rates.
If your evaluation only checks the final string, you remain blind to these factors, as well as whether a change you shipped to the library—such as a CLI improvement, better error messages, or a new Skill—actually helped agents.
Our goal with this harness is to evaluate the amount of work an agent must perform to complete a given task and whether changes to the library improve performance.
How do we run evaluations?
A few words on our evaluation methodology.
We run every task under three variants (or “tiers”); three different ways an agent can interact with
transformers
:
bare pip install transformers, and nothing else clone the full transformers source, checked out in the working directory skill a packaged Skill: the CLI's docs + task examples, loaded in context
These are not nested:
skill
does not contain
clone
(it ships curated docs, not the source tree), and neither strictly contains the other; each provides a different kind of assistance. As we will see, a model can sometimes perform better on
clone
than on
skill
.
Additional choices include:
- For now, we focus only on deterministic tasks which can provide an exact match, offering a solid ground for experimentation. Model-as-a-judge and other schemes are the obvious next steps for other tasks.
- Every run is its own Hugging Face Job: one per (model × revision × task), so the entire sweep runs in parallel on identical hardware, keeping the comparison fair at scale.
- Results and traces land in a Hugging Face Bucket: fast, no versioning needed, and capable of handling very high write concurrency.
Which models to benchmark against?
Not all models driving agents are equal, and their differences change what you should look for when running them.
Large open models
At one end, you have the largest, most capable open models. On reasonably common tasks, these should eventually get the right answer. For them, task completion saturates near 100% and stops telling you much about your tool; a more relevant benchmark is the effort it took the agent to get there: how many turns, tokens, and seconds it required, and whether they followed a clean path or used deprecated APIs.
Local
Local models vary widely in size, and so do their abilities. Metrics such as “match %” are more relevant here than for their larger counterparts, as you can see how model sizes and capabilities affect results on your specific tool.
This harness not only provides guidance to library maintainers on how to improve a repository for agent interactions, it also helps assess how different agents and models perform on the tasks users care about.
The harness scores every run on several axes, so you can ask what actually matters for each class of model:
- match %: did the final answer contain the expected result (per-task, case-insensitive substring / regex / exact, all explicit in the report);
- median time and median tokens (new vs. cached vs. generated);
- runs with error %: including a guard that flags runs which produced nothing (0 output tokens, no tool calls, no answer) so silent failures don’t masquerade as “0”;
- marker adoption: tool-defined behavior markers; see below for an explanation of what this is.
All of this lands in a report you can directly examine, with Overview, Coverage, and Results available client-side.
And because it captures the native agent trace of every run, numbers are just the beginning: you can read exactly what the agent did, command by command. The traces are shareable through the Hub’s agent-traces viewer.
Before the results, a quick recap of the setup. Each run varies four things: the model driving the agent, the
transformers
revision it runs against, the task, and the tier (
bare
/
clone
/
skill
).
Large open models: hold the model, vary the revision
Since a large open model will usually get to the correct result, what you’re really measuring is the effort it took to do so. Did it take ten turns or one? Did it follow an API path you deprecated because it trusted obsolete documentation? Did it hit an error you hadn’t foreseen?
The natural experiment is to fix one strong model and vary the tool’s revisions: the successive git versions of
transformers
we test against, from released tags like
v5.8.0
and
v5.9.0
to the specific commit that introduces the CLI and Skill. We want to watch whether the load it puts on the agent goes up or down. We used the harness on
transformers
to check whether adding a dedicated CLI and Skill actually lightened the agents’ work.
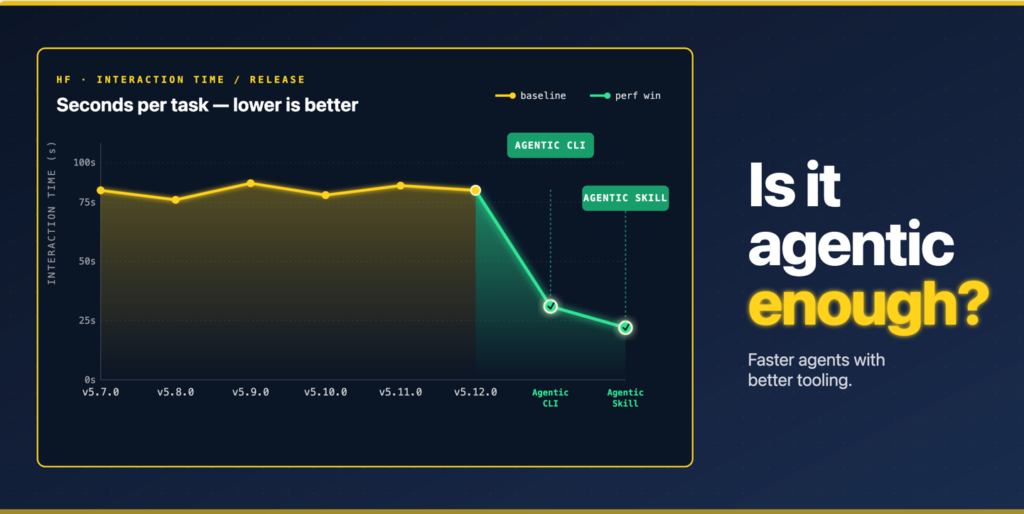
For the three large models we used in our tests, the average time spent on all tasks indicates that the Skill commit results in less time spent working on the tasks:
Median time per revision, by tier: the skill commit (green dot) is the fastest.
On the other hand, in the experiments in which we cloned the repository, we can see a significant increase in token consumption due to the commit that introduced the CLI and examples.
Stay ahead of AI. Get the most important stories delivered to your inbox — no spam, no noise.


