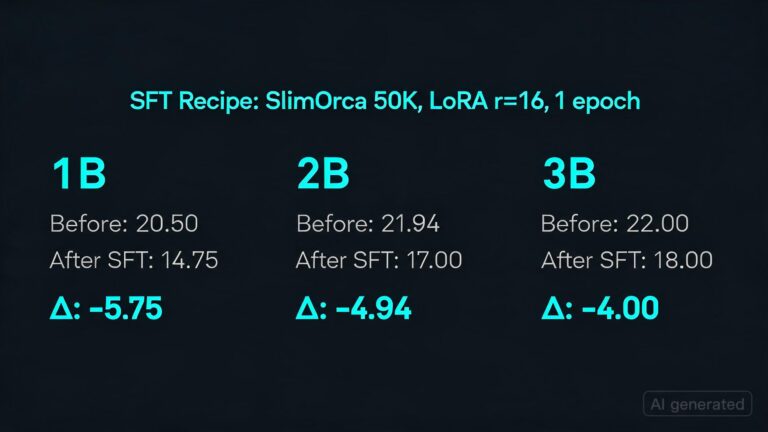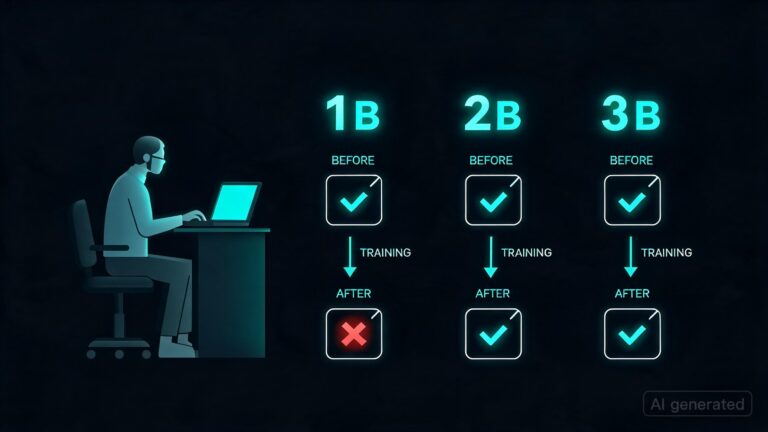
**What Happened:** A Reddit user, GPUburnout, conducted an experiment where they trained three language models (LMs), one with 1 billion parameters, another with 2 billion, and the final one with 3 billion parameters. The objective was to evaluate if these LMs could follow instructions effectively after a self-tuning procedure known as “self-supervised fine-tuning” (SFT). The results showed mixed outcomes: while the larger models improved slightly in instruction following, the smallest model actually declined in performance. Specifically, the 1 billion parameter model’s Instruction Following Evaluation (IFEval) score dropped from 20.5 to 14.75 after SFT.
**Why It Matters:** This experiment highlights a critical issue within large language models-specifically their ability to maintain or improve instruction-following capabilities as they are scaled up in size. The observed decline in performance on the smallest model suggests that smaller LMs may struggle more with maintaining fidelity and robustness, especially when it comes to following instructions. This finding underscores the need for further research into how different model sizes might affect their ability to adhere to specific tasks or guidelines. It also points towards potential limitations of scaling up models without careful consideration of these nuances.
– The experiment revealed a significant drop in instruction-following performance for the smallest model after SFT.
– There is a need for more studies to understand why this happens and how smaller LMs can be improved.
– Further investigation into using different training settings, such as varying learning rates, could provide insights.