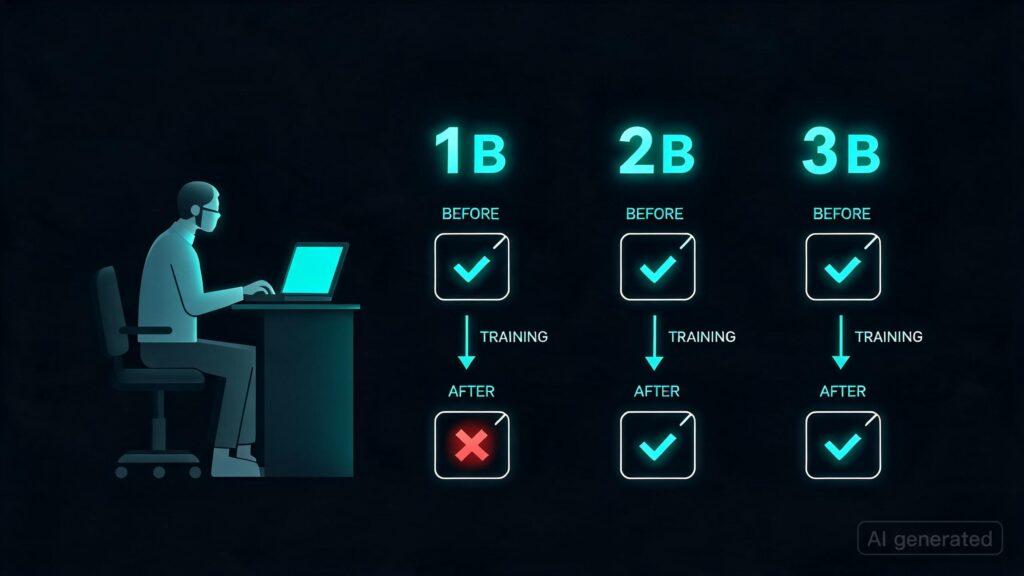
**What Happened:**
A Reddit user, GPUburnout, conducted an experiment where they trained three language models (1B, 2B, and 3B parameters) using a standard SFT (Self-Supervised Fine-Tuning) approach. The goal was to see how well these models could follow instructions after training. However, the results were unexpected—it appears that the smallest model (1B) actually performed worse than before the fine-tuning process. The 2B parameter model showed some improvement but still struggled with instruction-following. The largest model (3B) improved slightly. This finding suggests that smaller models might have difficulty adhering to instructions after being trained on large datasets.
**Why It Matters:**
This experiment highlights a critical challenge in the development of language models: their ability to follow specific instructions can degrade, especially for smaller models. Previous research often assumes improvements in instruction-following with larger model sizes due to better generalization capabilities. However, this case shows that even very small models might lose this capability. Understanding and addressing this issue is crucial for ensuring robustness in applications where precise execution of tasks is essential.
– Smaller language models may struggle more with maintaining their ability to follow instructions.
– The effectiveness of fine-tuning methods needs further investigation across different model sizes.
– Future research should focus on mechanisms that ensure instruction-following even in smaller, potentially less resource-intensive models.
Stay ahead of AI. Get the most important stories delivered to your inbox — no spam, no noise.


