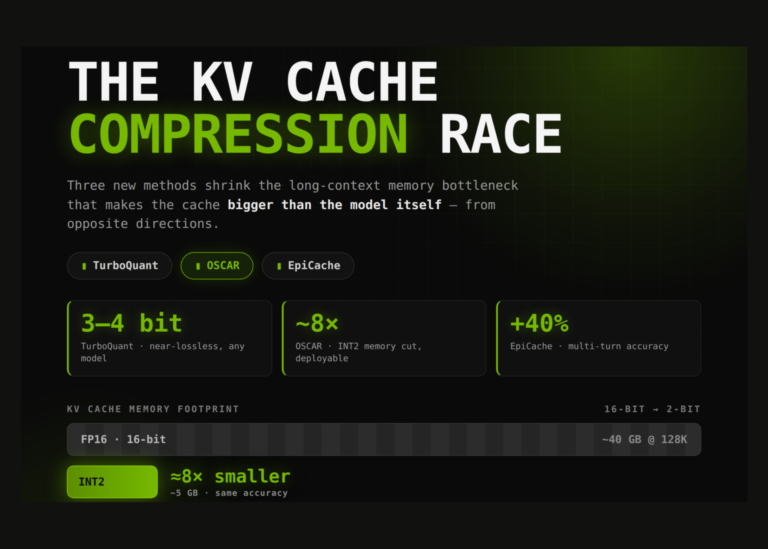
“`html
Here are my KV cache quantization benchmarks: TurboQuant is overrated but saved by TCQ, q5 deserves more attention, and symmetric q8 might be a waste of VRAM
Welcome to the world of BeeLlama v0.1.2 and my single RTX 3090 as we explore PPL and KLD benchmarks with a focus on our 24 GB VRAM setup.
I have thoroughly re-examined these tests to ensure they are grounded in real-world usage, particularly for models like Qwen 3.6 27B (Q5_K_S and IQ4_XS) at 64k and 128k context lengths.
PPL Hides the Tail, KLD Exposes It
- PPL keeps performance close to
bf16. Even with TurboQuant’s quantization methods liketurbo3_tcq, PPL only adds a small margin. However,q4_0has a significant tail issue compared toq5_0. This is crucial as it affects the quality of tool calls and JSON structures.
Rotation Closed the Gap at 4 Bits
- TurboQuant’s value lies in its ability to apply rotation before quantization, which is similar to what
turbo4does. At 4 bits, TurboQuant doesn’t offer a quality improvement over plainq4_0, saves no memory, and runs slower by 17%. For cases requiring aggressive compression, TCQ (turbo3_tcq) is where TurboQuant shines.
TCQ Saves the Low End
- TurboQuant’s
turbo3_tcqandturbo2_tcqare significantly better than their non-TCQ counterparts. These methods are essential for scenarios where memory savings are critical, such as in environments with limited VRAM.
Asymmetric KV Beats Symmetric at the Same Size
- TurboQuant’s asymmetric quantization (q5_0/q4_1) outperforms symmetric quantization (q4_0/q4_1) across all test configurations. This is especially true once key memory usage reaches
q5_0, where the next bit goes to value rather than further reducing key space.
Higher Model Precision Means More Cache Damage
- The impact of model precision on cache damage is significant. For instance,
Q5_K_Suses 3-5% more memory thanIQ4_XSto achieve the same level of 99.9% precision.
q8 Is Mostly a Luxury Tier
- For models like Qwen, q8 quantization (53.1%) at 43.8% of
bf16is often more about validation than practical use. It’s best reserved for cases where you have ample VRAM to spare and need the highest precision without worrying about cache size constraints.
Key Takeaways
- TurboQuant’s value lies in its ability to apply rotation before quantization, which can be a game-changer for memory savings.
- TCQ is particularly valuable when aiming for aggressive compression in environments with limited VRAM.
- Asymmetric quantization outperforms symmetric methods once key memory usage reaches
q5_0. - Higher model precision can lead to more cache damage, highlighting the importance of balancing both model and key space quantizations.
“`
Source Read original →