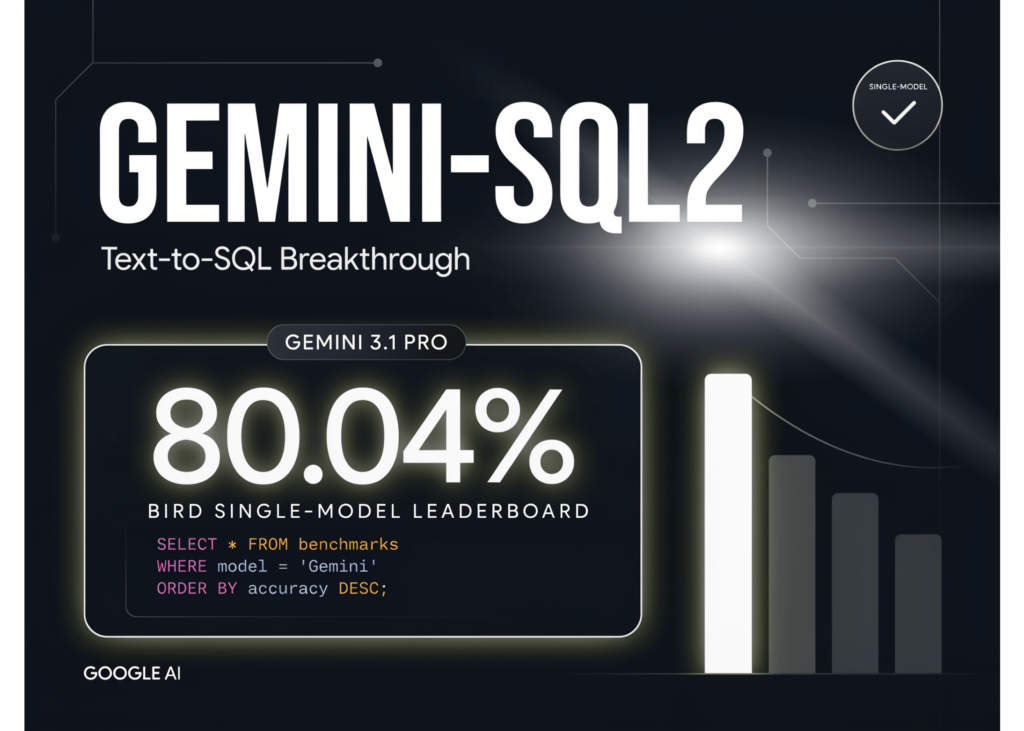
For developers and data analysts, the release of Gemini-SQL2 on X marks a significant shift in how natural language translates to database commands. Powered by Gemini 3.1 Pro, this system now achieves 80.04% execution accuracy on the BIRD Text-to-SQL Leaderboard (Single Model). Google’s own chart positions this new capability ahead of its previous iteration, Gemini-SQL. Crucially, this metric tracks whether the generated SQL actually runs and returns correct data, not merely whether the syntax appears valid.
Gemini-SQL2
Gemini-SQL2 is not a standalone foundation model but a specific text-to-SQL capability built upon Gemini 3.1 Pro. It converts natural language inquiries into what Google terms ‘execution-ready SQL queries.’
According to the announcement on X, “data subtlety & complex business contexts make generating accurate SQL from natural language notoriously hard.” The post further noted that “improved SQL understanding can elevate natural language skills across Google’s data services.” This suggests integration targets such as BigQuery Studio, AlloyDB AI, and Cloud SQL Studio, which already feature Gemini-based SQL generation. Google has not yet confirmed which specific products will receive the Gemini-SQL2 update.
Benchmarks
BIRD (BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation) serves as the industry standard for this task. It comprises 12,751 question-SQL pairs across 95 databases spanning 37 professional domains, totaling 33.4GB. Unlike older benchmarks such as Spider, these databases contain dirty values and require external knowledge grounding.
BIRD measures execution accuracy (EX): the generated SQL must run and return results matching the gold query. Google confirmed this directly. “Per the BIRD benchmark, which measures execution-verified accuracy, GeminiSQL-2’s SQL doesn’t just look right, it also runs successfully.”
The Single Trained Model Track restricts preprocessing, retrieval, and agentic frameworks that ensembles use to boost scores, measuring the model’s core text-to-SQL ability. Google Cloud’s prior record on this track, reported November 15, 2025, was 76.13. Google benchmarks human performance at 92.96, leaving a 12.92-point gap from 80.04.
How the Leaderboard Stacks Up
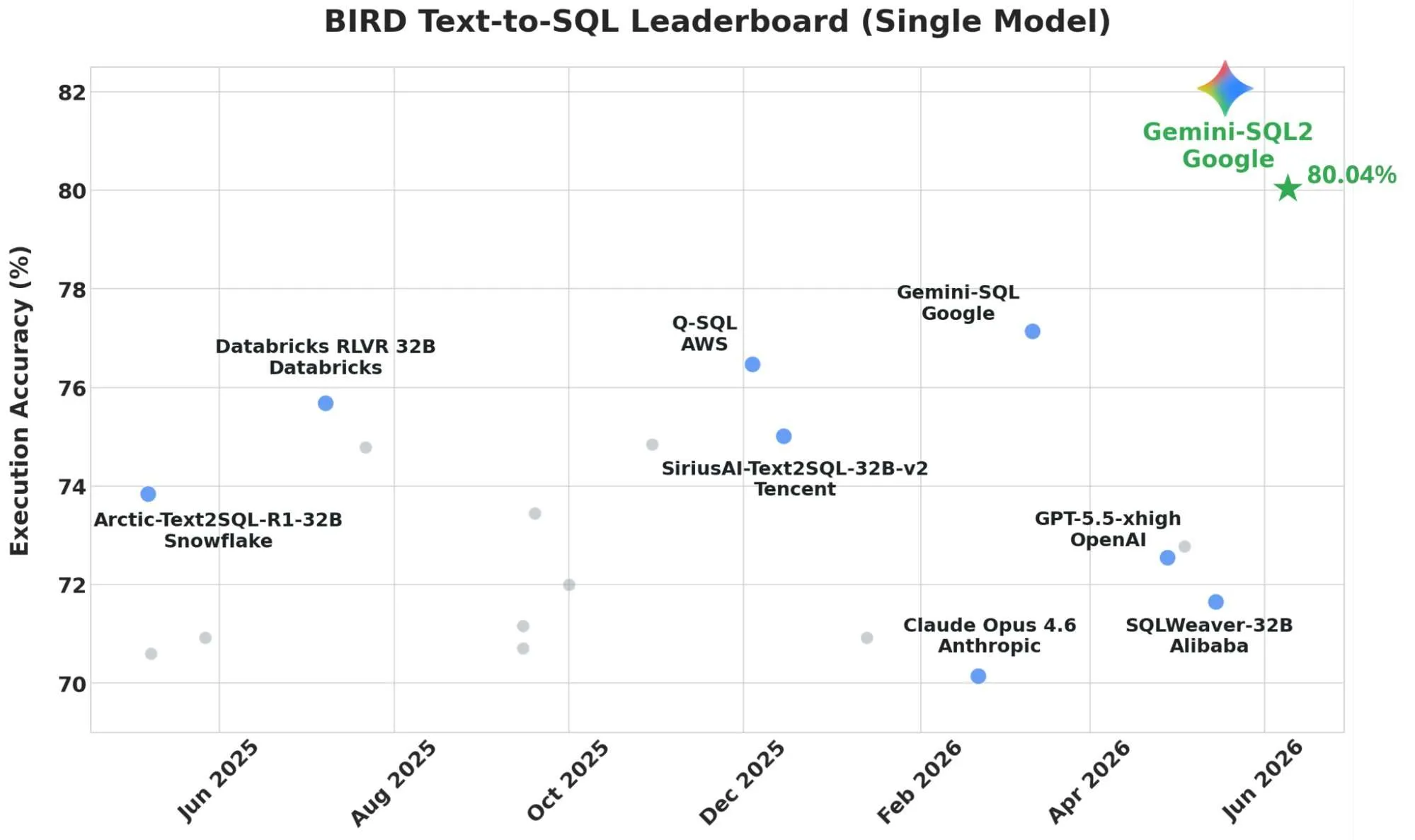
Google’s chart, on X post, shows Gemini-SQL2 ahead of eight named competitors, along with several unlabeled points. Only 80.04% is stated as text. The values below are read from the chart’s position and are approximate; dates reflect each point’s horizontal placement.
| System | Organization | BIRD Execution Accuracy (Single Model) | Chart Date |
|---|---|---|---|
| Gemini-SQL2 | 80.04% (stated) | Jun 2026 | |
| Gemini-SQL | ~77.2% | Mar 2026 | |
| Q-SQL | AWS | ~76.5% | Dec 2025 |
| Databricks RLVR 32B | Databricks | ~75.7% | Jul 2025 |
| SiriusAI-Text2SQL-32B-v2 | Tencent | ~75.0% | Dec 2025 |
| Arctic-Text2SQL-R1-32B | Snowflake | ~73.9% | Jun 2025 |
| GPT-5.5-xhigh | OpenAI | ~72.5% | Apr 2026 |
| SQLWeaver-32B | Alibaba | ~71.7% | May 2026 |
| Claude Opus 4.6 | Anthropic | ~70.1% | Feb 2026 |
Two patterns are visible. Google now holds the top two named positions, Gemini-SQL2 and Gemini-SQL. Several specialized 32B SQL models also sit above some general frontier models on this chart.
Use Cases with Examples
- Self-service analytics: A revenue manager asks for monthly recurring revenue by region, for accounts that churned within 90 days of upgrade. This needs joins, window logic, and date arithmetic. Execution-verified generation catches SQL that runs but returns wrong rows.
- Data engineering drafts: Devs can draft BigQuery transformations from English, then review rather than write from scratch. Google’s November 2025 work identified schema understanding as the hard part. Higher BIRD scores reflect better handling of ambiguous columns and messy values.
- Embedded “ask your data” features: SaaS teams adding natural-language query interfaces still need human review at 80% accuracy. One in five queries can be wrong. The score sets expectations, not a removal of review.
Gemini-SQL2 Launch: Community Reception Dashboard
Gemini-SQL2 Launch: Community Reception Dashboard
Verified public engagement on Google Research’s announcement posts • first ~3 hours • Jun 12, 2026
X / Twitter (main post)
LinkedIn (main post)
Reception signal
More in AI Tools & Reviews


