

Google DeepMind has launched Gemma 4 12B, a dense multimodal model that eliminates the need for separate vision and audio encoders. Instead, visual and sonic data flow directly into the LLM backbone. The result is an agentic workflow engine capable of running on a standard consumer laptop with 16 GB of RAM. It is released under the Apache 2.0 license.
Model Overview & Access
Gemma 4 12B is a 12-billion-parameter decoder-only transformer. It natively processes text, images, audio, and video without relying on external encoders. The decoder mirrors the structure of the Gemma 4 31B Dense model, effectively bridging the gap between the edge-optimised E4B and the larger 26B Mixture of Experts variant.
- Architecture: A unified, encoder-free decoder-only transformer.
- Modalities: Text, image, video, and native audio input — marking the first mid-sized Gemma to support audio natively.
- Hardware requirement: Requires 16 GB of VRAM or unified memory. Compatible with consumer GPU laptops and Apple Silicon Macs.
- License: Apache 2.0. Weights are open and publicly downloadable.
- Inference stack: Compatible with llama.cpp, MLX, vLLM, Ollama, SGLang, Unsloth, and LM Studio.
- Download: Available on Hugging Face and Kaggle. The instruct variant is
google/gemma-4-12B-it. - Integration: Supports Hugging Face Transformers, LiteRT-LM CLI, and an OpenAI-compatible local API server via
litert-lm serve.
A dedicated Multi-Token Prediction (MTP) drafter model is also included to reduce inference latency on local hardware.
Architecture: The Encoder-Free Design
Previous mid-sized Gemma models relied on separate Transformer encoders for vision and audio, adding latency and parameter overhead. The medium-sized Gemma 4 models typically carried a 550M-parameter vision encoder, while the E2B and E4B variants included a 300M-parameter audio encoder. All of that complexity is removed in the 12B model.
Vision embedder (35M parameters): Raw images are segmented into 48×48 pixel patches. Each patch is projected into the LLM’s hidden dimension using a single matrix multiplication. There is no attention layer; each patch is processed independently. Spatial position is injected via a factorized coordinate lookup: a learned X matrix and a learned Y matrix. For a patch at (x, y), the model retrieves two learned embeddings and adds them to form a position vector. This is added to the patch embedding, followed by normalization. That constitutes the entire vision pipeline.
Audio wave projection: Raw 16 kHz audio is sliced into 40 ms frames. Each frame contains 640 values, which are linearly projected into the same embedding space as text tokens. There is no feature extraction and no conformer layers. The LLM’s existing Rotary Position Embedding (RoPE) manages the 1-D temporal sequence. The audio encoder found in the E2B and E4B models, which used 12 conformer layers, has been entirely removed.
Importance: The unified weight space means you no longer need to co-tune separate frozen encoders. Downstream fine-tuning with LoRA or full tuning updates vision, audio, and text processing in a single pass. Hugging Face Transformers and Unsloth already support this.
The encoder-free design reduces multimodal latency. The LLM backbone begins processing immediately, without waiting for an encoder to finish first.
Capabilities & Performance
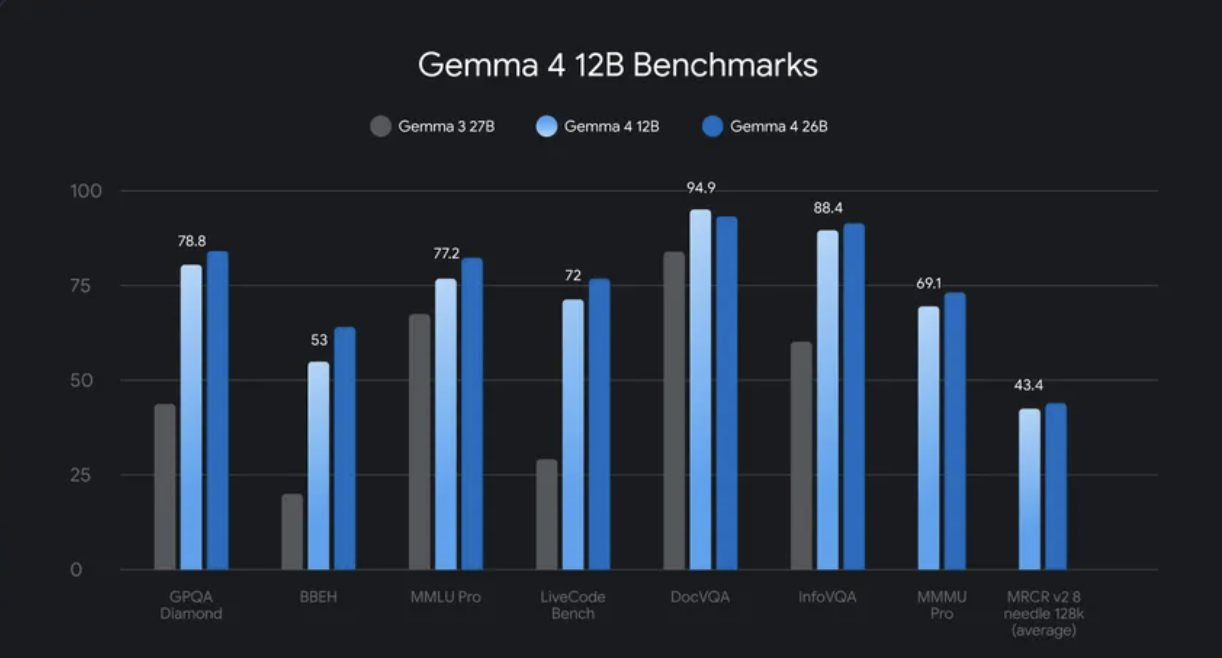
Google DeepMind has not published full benchmark results in the initial launch materials. The official release notes state the 12B model performs nearly as well as the 26B MoE model on standard benchmarks, at less than half the total memory footprint.
The model’s demonstrated capabilities include:
- Automatic speech recognition. Transcribes audio natively without an external ASR pipeline.
- Agentic reasoning. Runs multi-step workflows locally, with performance approaching the 26B MoE model.
- Diarization. Distinguishes speakers in audio input.
- Video understanding. Processes video frames alongside audio. A demo analyzed a 5-minute Google I/O keynote segment using 313 frames at 1 FPS with a visual token budget of 70 per frame.
- Coding. Built a Gradio image-processing app using its own code generation, served locally with llama.cpp.
- Multimodal agentic workflows. The official Gemma Skills repository at github.com/google-gemma/gemma-skills provides pre-built agent capabilities.
In Google’s own Google AI Edge Eloquent app, the switch to Gemma 4 12B produced what Google reports as a 60%+ jump in overall quality, with improved instruction following and scope adherence.
Marktechpost’s Visual Explainer
More in AI Music


