
“`html
Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling

What if a reasoning model could decide for itself when to decompose and parallelize independent subtasks, how many concurrent threads to spawn, and how to coordinate them based on the problem at hand? We provide a detailed analysis of recent progress in the field of parallel reasoning, especially Adaptive Parallel Reasoning.
Disclosure: this post is part landscape survey, part perspective on adaptive parallel reasoning. One of the authors (Tony Lian) co-led ThreadWeaver (Lian et al., 2025), one of the methods discussed below. The authors aim to present each approach on its own terms.
Motivation
Recent progress in LLM reasoning capabilities has been largely driven by inference-time scaling, in addition to data and parameter scaling (OpenAI et al., 2024; DeepSeek-AI et al., 2025). Models that explicitly output reasoning tokens (through intermediate steps, backtracking, and exploration) now dominate math, coding, and agentic benchmarks. These behaviors allow models to explore alternative hypotheses, correct earlier mistakes, and synthesize conclusions rather than committing to a single solution (Wen et al., 2025).
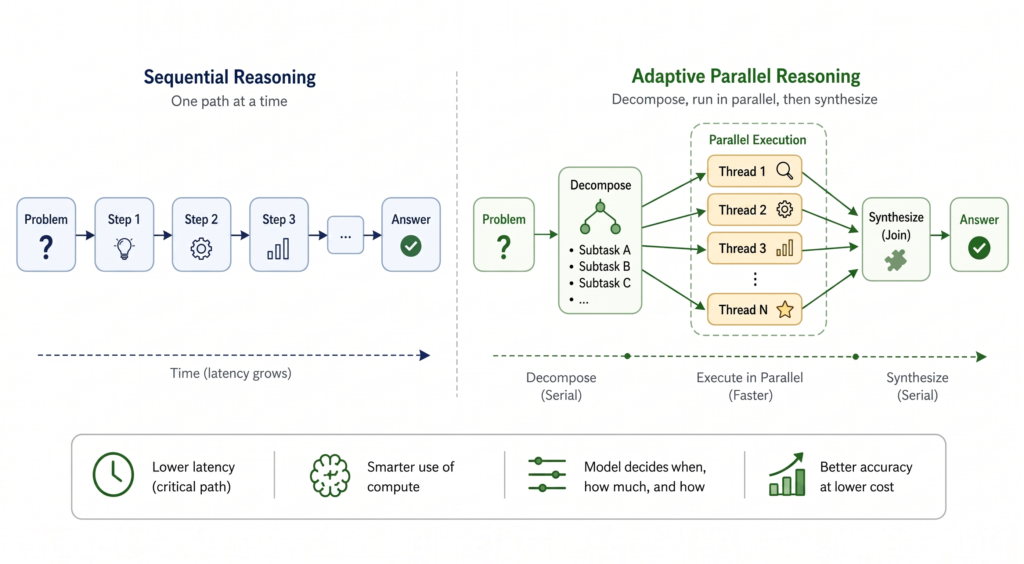
The problem is that sequential reasoning scales linearly with the amount of exploration. Scaling sequential reasoning tokens comes at a cost, as models risk exceeding effective context limits (Hsieh et al., 2024). The accumulation of intermediate exploration paths makes it challenging for the model to disambiguate amongst distractors when attending to information in its context, leading to a degradation of model performance, also known as context-rot (Hong, Troynikov and Huber, 2025). Latency also grows proportionally with reasoning length. For complex tasks requiring millions of tokens for exploration and planning, it’s not uncommon to see users wait tens of minutes or even hours for an answer (Qu et al., 2025). As we continue to scale along the output sequence length dimension, we also make inference slower, less reliable, and more compute-intensive. Parallel reasoning has emerged as a natural solution. Instead of exploring paths sequentially (Gandhi et al., 2024) and accumulating the context window at every step, we can allow models to explore multiple threads independently (threads don’t rely on each other’s context) and concurrently (threads can be executed at the same time).

Over recent years, a growing body of work has explored this idea across synthetic settings (e.g., the Countdown game (Katz, Kokel and Sreedharan, 2025)), real-world math problems, and general reasoning tasks.
From Fixed Parallelism to Adaptive Control
Existing approaches show that parallel reasoning can help, but most of them still decide the parallel structure outside the model rather than letting the model choose it.
- Simple fork-and-join.
- Self-consistency/Majority Voting, independently sample multiple complete reasoning traces, extract final answer from each, and return the most common one (Wang et al., 2023).
- Best-of-N (BoN), similar to self-consistency, but uses a trained verifier to select the best solution instead of using majority voting (Stiennon et al., 2022).
- Although simple to implement, these methods often incur redundant computation across branches since trajectories are sampled independently.
- Heuristic-based structured search.
- Tree / Graph / Skeleton of Thoughts, a family of structured decomposition methods that explores multiple alternative “thoughts” using known search algorithms (BFS/DFS) and prunes via LLM-based evaluation (Yao et al., 2023; Besta et al., 2024; Ning et al., 2024).
- Monte-Carlo Tree Search (MCTS), estimates node values by sampling random rollouts and expands the search tree with Upper Confidence Bound (UCB) style exploration-exploitation (Xie et al., 2024; Zhang et al., 2024).
- These methods improve upon simple fork-and-join by decomposing tasks into non-overlapping subtasks; however, they require prior knowledge about the decomposition strategy, which is not always known.
- Recent variants.
- ParaThinker, trains a model to run in two fixed stages: first generating multiple reasoning threads in parallel, then synthesizing them. They introduce trainable control tokens (
<think_i>) and thought-specific positional embeddings to enforce independence during reasoning and controlled integration during summarization via a two-phase attention mask (Pan et al., 2025). - GroupThink, multiple parallel reasoning threads can see each other’s partial progress at token level and adapt mid-generation. Unlike prior concurrent methods that operate on independent requests, GroupThink runs a single LLM producing multiple interdependent reasoning trajectories simultaneously (Hsu et al., 2025).
- Hogwild! Inference, multiple parallel reasoning threads share KV cache and decide how to decompose tasks without an explicit coordination protocol. Workers generate concurrently into a shared attention cache using RoPE to stitch together individual KV blocks in different orders without recomputation (Rodionov et al., 2025).

The methods above share a common limitation: the decision to parallelize, the level of parallelization, and the search strategy are imposed on the model, regardless of whether the problem actually benefits from it. However, different problems need different levels of parallelization, and that is something critical to the effectiveness of parallelization. For example, a framework that applies the same parallel structure to “What’s 25+42?” and “What’s the smallest planar region in which you can continuously rotate a unit-length line segment by 180°?” is wasting compute on the former and probably using the wrong decomposition strategy for the latter. In the approaches described above, the model is not taught this adaptive behavior. A natural question arises: What if the model could decide for itself when to parallelize, how many threads to spawn, and how to coordinate them based on the problem at hand?
Adaptive Parallel Reasoning (APR) answers this question by making parallelization part of the model’s generated control flow. Formally defined, adaptivity refers to the model’s ability to dynamically allocate compute between parallel and serial operations at inference time. In other words, a model with adaptive parallel reasoning (APR) capability is taught to coordinate its control flow, when to generate sequences sequentially versus in parallel.
It’s important to note that the concept of adaptive parallel


