NVIDIA NeMo AutoModel delivers 3.4 to 3.7 times higher training throughput and 29 to 32 percent less GPU memory when fine-tuning MoE models compared to native Transformers v5. This gain comes from a single import line and requires no other code changes.
Why MoE models need special handling
Models with Mixture of Experts (MoE) route tokens across hundreds of expert sub-networks. Efficient training demands fusing expert matrix multiplications into one kernel, sharding weights across GPUs, and overlapping communication with computation. General-purpose libraries do not provide this infrastructure out of the box.
Transformers v5 introduced first-class MoE support, including expert backends, dynamic weight loading, and tensor parallel plans. It also integrated PyTorch’s DeviceMesh directly into the from_pretrained function to make distributed training easier.
NeMo AutoModel builds on v5 by subclassing AutoModelForCausalLM. It adds Expert Parallelism, DeepEP fused all-to-all dispatch, and TransformerEngine kernels. DeepEP overlaps communication with expert compute, a capability missing in v5. The library relies on v5’s reversible weight conversion to load models, focusing engineering on reusable core operations rather than per-model checkpoint plumbing. The save_pretrained function still emits standard HuggingFace checkpoints compatible with tools like vLLM and SGLang.
Same API, more performance
NeMo AutoModel subclasses AutoModelForCausalLM to ensure API compatibility with the HuggingFace Transformers community. Code that works with HF models works with AutoModel.
Loading a model changes only the import statement. For popular MoE architectures like Qwen3, NVIDIA Nemotron, GPT-OSS, and DeepSeek V3, NeMo AutoModel ships hand-tuned implementations with TransformerEngine attention, fused linear layers, and custom expert kernels. For other models, it falls back to vanilla HF while applying optimizations like Liger kernel patching. The resulting model is ready to scale; pass a device_mesh and you have multi-GPU training without further rewrites.
To train Nemotron 3 Nano 30B A3B with Expert Parallelism across eight GPUs, one adds the distributed mesh configuration:
import os
import torch
import torch.distributed as dist
from nemo_automodel import NeMoAutoModelForCausalLM
from nemo_automodel.recipes._dist_utils import create_distributed_setup_from_config
dist.init_process_group(backend="nccl")
torch.manual_seed(0)
torch.cuda.set_device(int(os.environ.get("LOCAL_RANK", 0)))
dist_setup = create_distributed_setup_from_config(
{
"strategy": "fsdp2",
"ep_size": 8,
},
)
model = NeMoAutoModelForCausalLM.from_pretrained(
"nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-BF16",
dtype=torch.bfloat16,
distributed_setup=dist_setup,
)
dist.destroy_process_group()
This setup provides speed, scalability, and memory optimizations with FSDP2, Expert Parallelism, TransformerEngine kernels, and DeepEP dispatch, all from a from_pretrained call.
Performance results
Evaluation covered two regimes: full fine-tuning a 550B model across 16 nodes and training two 30B MoE models on a single node. The 550B result demonstrates why Expert Parallelism is essential at scale. The 30B results quantify per-GPU speedup over Transformers v5.
Nemotron 3 Ultra 550B A55B full fine-tune
Nemotron 3 Ultra 550B A55B is a 550B-parameter hybrid model shipping with Mamba2, LatentMoE, and Multi-Token Prediction (MTP). The benchmark covers a full fine-tune where every parameter is updated and the Adam optimizer state is materialized. This spans 16 H100 nodes (128 GPUs).
Methodology:
| Parameter | Value |
|---|---|
| Hardware | 16x H100 80GB (128 GPUs) |
| Expert Parallelism | EP=64 |
| Local batch size | 2 |
| Sequence length | 4,096 |
| Features | MTP, activation checkpointing, fused linear cross-entropy |
| Kernels | DeepEP dispatch + torch_mm experts + TransformerEngine |
| Metric | NeMo AutoModel (EP=64) |
|---|---|
| TPS/GPU (avg) | 815 |
| TFLOP/s/GPU | ~293 |
| Peak Memory | 58.2 GiB |
Transformers v5 runs out of memory at this scale, so there is no v5 number to report here. AutoModel’s Expert Parallelism shards the experts across GPUs to bring the footprint within budget. The 30B comparisons below show the same advantage where v5 fits.
Single-node 30B MoE benchmarks
Benchmarking occurred on a single node with eight H100 80GB GPUs. Methods included HF Transformers v4 (hub code), HF Transformers v5 (with best available optimizations), and NeMo AutoModel (EP=8 + custom kernels).
Methodology:
| Parameter | Value |
|---|---|
| Hardware | 8x H100 80GB (single node) |
| Sequence length | 4,096 |
| Local batch size | 1 |
NeMo AutoModel numbers use a balanced routing gate, forcing tokens to distribute uniformly across experts. This emulates the ideal operating point an MoE is trained toward. A well-trained model’s load-balancing loss drives expert utilization to near-uniform, so balanced routing reflects the steady-state a real workload converges to. It removes the straggler noise that random dummy tokens otherwise inject into expert parallelism. v4 and v5 run their native router on the same dummy tokens. The balanced gate measures NeMo AutoModel at its target MoE operating point, while v4 and v5 columns reflect their out-of-the-box behavior.
Qwen3-30B-A3B
| Metric | v4 | v5 (FA2 + grouped_mm) | NeMo AutoModel (EP=8) | v5 → NeMo AutoModel |
|---|---|---|---|---|
| TPS/GPU (avg) | deadlock | 3,075 | 11,340 | 3.69x |
| Peak Memory | — | 68.2 GiB | 48.1 GiB | -29% |
| Avg Forward+Loss | — | 582 ms | 194 ms | 3.00x |
| Avg Backward | — | 758 ms | 178 ms | 4.26x |
Transformers v4 deadlocks because it stores Qwen3 MoE experts as a ModuleList of 128 individual MLP modules, each separately FSDP-wrapped. The forward pass uses a data-dependent loop that only iterates experts that received tokens. With different data per rank, different ranks skip different experts, causing mismatched FSDP AllGather/ReduceScatter collectives and an indefinite hang. Transformers v5 fixes this by storing experts as fused 3D parameter tensors, avoiding per-expert modules and per-expert FSDP collectives.
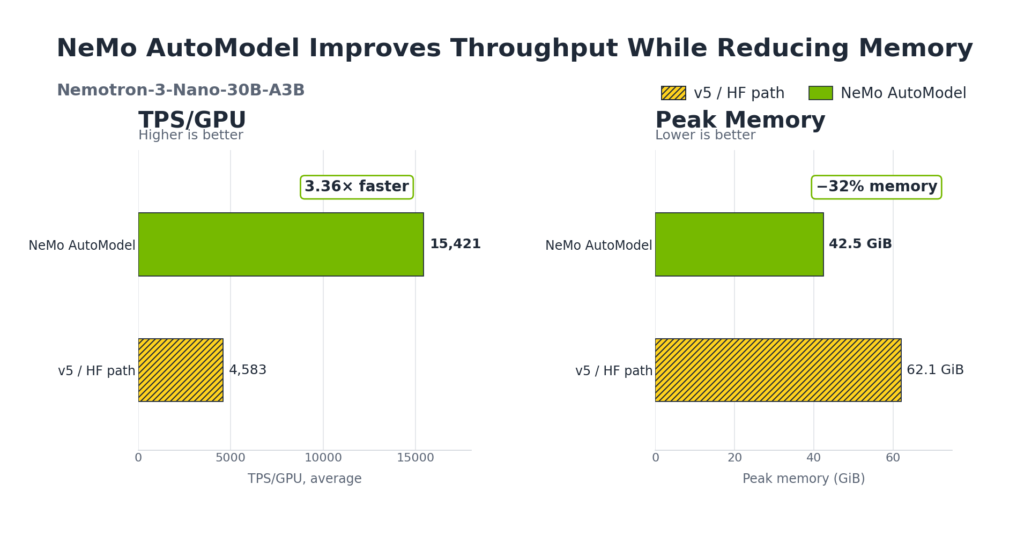
Nemotron 3 Nano 30B A3B
| Metric | v4 (hub code) | v5 (FA2 + grouped_mm + Mamba CUDA) | NeMo AutoModel (EP=8) | v5 → NeMo AutoModel |
|---|---|---|---|---|
| TPS/GPU (avg) | 1,807 | 4,583 | 15,421 | 3.36x |
| Peak Memory | 61.9 GiB | 62.1 GiB | 42.5 GiB | -32% |
| Avg Forward+Loss | 1,024 ms | 283 ms | 109 ms | 2.60x |
| Avg Backward | 1,246 ms | 611 ms | 157 ms | 3.89x |
v4 config uses trust_remote_code=True for NVIDIA’s hub modeling code. The hub code’s expert loop is FSDP-safe because it iterates all experts regardless of token assignment, so it does not deadlock like Qwen3 v4.
Source of speedup
The 3.4 to 3.7 times speedup from NeMo AutoModel over Transformers v5 comes from three sources:
- Expert Parallelism reduces memory pressure. EP=8 distributes expert weights across GPUs, cutting the per-GPU MoE footprint by eight times. For Qwen3, this drops peak memory from 68.2 GiB to 48.1 GiB (-29%). For Nemotron Nano, it drops from 62.1 GiB to 42.5 GiB (-32%), freeing headroom for larger batch sizes or longer sequences.
- DeepEP fuses communication with computation. Instead of separate AllGather/Source Read original →