Olmo Hybrid predicts nouns and verbs better than Olmo 3
Olmo Hybrid beats Olmo 3 on content words but falls short when a model needs to copy a phrase exactly as it appeared earlier.
Allen Institute for AI researchers have compared a new hybrid architecture against their standard transformer model, Olmo 3. The two systems use the same data, tokenizer, and training recipe, meaning any difference in performance stems from the architecture itself.
The headline numbers show hybrids can match or beat transformers on standard benchmarks. However, these figures do not reveal specific advantages at the token level.
The team ran a head-to-head comparison using fine-grained analysis of model predictions across different token types. This approach isolates the strengths of hybrid models over standard transformers.
Olmo Hybrid shows a clear advantage on tokens that carry meaning, such as nouns, verbs, and adjectives. It also performs better on tokens requiring context, like pronouns referring to a specific person.
The hybrid’s advantage almost vanishes on tokens that simply repeat information already in the input. This is where the transformer’s strength lies, as it can recall exact earlier tokens.
Attention versus recurrence, and measuring the difference
A language model consists of a stack of layers that refine the representation of every token using surrounding tokens.
A transformer uses attention in every layer. This allows the model to draw directly on every earlier token at once, weighing relevance for the current prediction. Attention excels at recalling specific earlier tokens even when they appeared far back in the input.
The cost of attention climbs steeply as input grows because every token is compared against all earlier ones. While attention is strong at recalling and aggregating information, it struggles to represent information that evolves sequentially over time.
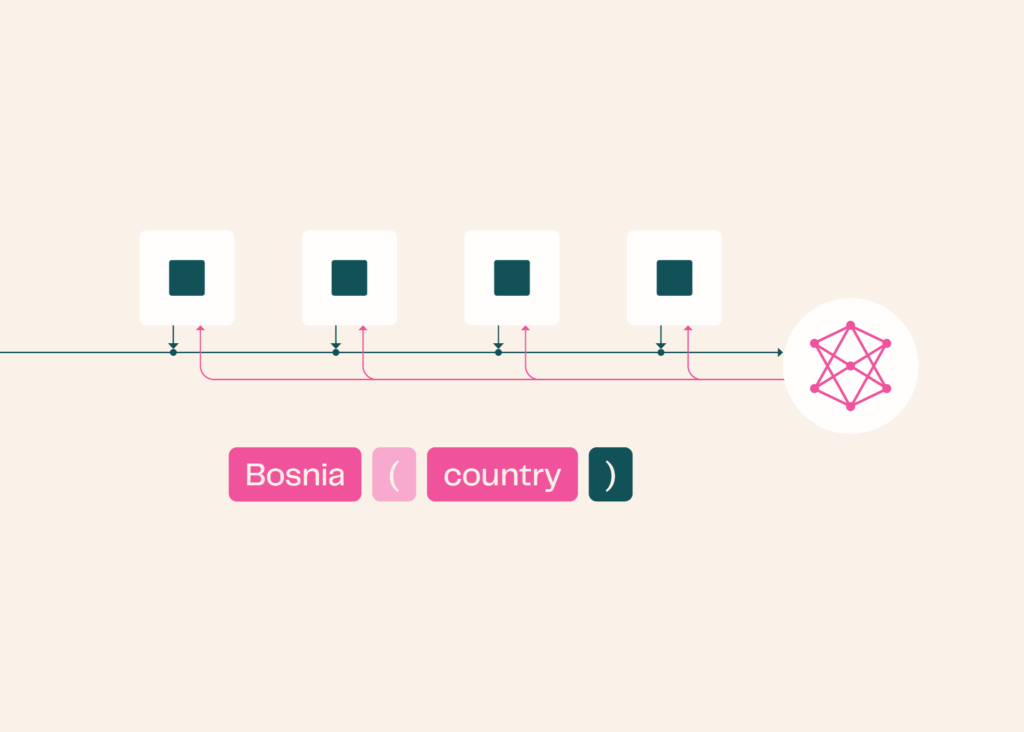
A hybrid model keeps a few attention layers but swaps the rest for recurrent layers. A recurrent layer reads tokens left to right and carries a fixed-size memory. It folds each new token into memory as it goes, keeping processing costs flat regardless of input length.
This memory is compressed and lossy, so a recurrent layer cannot reach back for an exact earlier token the way attention can. It is well suited to keeping a running account of anything that changes as the model reads tokens.
To isolate strengths and weaknesses, the team fed Olmo 3 and Olmo Hybrid passages of text including articles, Wikipedia entries, books, scientific papers, Python, HTML, and LaTeX.
Both models saw the same earlier tokens and assigned a probability to every possible next token. The team recorded the probability each gave to the token that actually followed.
They summarised the difference between the two models by computing the loss gap. A positive gap means the hybrid predicted the real next token better. A negative gap means the transformer did.
The team ran several analyses to find where loss gaps concentrated. They sorted each token into a category and averaged the loss gap within these categories. They re-checked each pattern with a regression to estimate the category’s own effect while holding other factors constant.
What real text shows
Olmo Hybrid has lower loss than Olmo 3 on most kinds of tokens, though not by the same amount on each.
In prose, the clearest divide is between content words and function words. The hybrid predicts content words better than the transformer, with a loss gap around 0.03, whereas the gap is closer to 0.01 on function words.
On content-word categories like adverbs and adjectives, the advantage of hybrid models is especially pronounced. Some function-word categories like existentials, such as “there”, also show a large advantage for hybrid models.
The hybrid’s edge is biggest on the words that say what a sentence is about and smallest on the grammatical words any model can nearly guess from syntax.
The advantage of hybrid models over transformers disappears in specific contexts. The first is closing, but not opening, braces. This pattern is robust across brackets in language, code, and markup. Attention suffices for representing bracket matching, suggesting attention alone suffices for closing brace prediction.
The second place where the hybrid’s advantage all but disappears is when the next token simply repeats something already in the passage. The team spots these cases by looking for repeated n-grams where the token that completes a sequence has appeared verbatim earlier.
The longer the repeated run, the smaller the hybrid’s lead, until it approaches zero.
The team explored using filtered losses on specific types of tokens to better compare architectures in pretraining experiments. They used three 1B-parameter models from earlier Olmo Hybrid work: a transformer, a hybrid, and a pure recurrent model with no attention at all.
On meaning-bearing tokens that aren’t repeats, the hybrid and pure recurrent model overtake the transformer, with the hybrid performing the best.
On repeated tokens, the pure recurrent model falls behind both the hybrid and the transformer because it has no attention to reach back for the copy.
These filtered token losses reveal different fine-grained differences between architectures, including copying abilities and differences on content words, early in training in a way that would not otherwise be visible.
Token-loss curves at WSD-annealed checkpoints
The team plotted token-loss curves at WSD-annealed checkpoints for a transformer, a hybrid, and a pure recurrent neural network, or RNN.
Two lessons follow from this work.
First, a single overall loss is too blunt to compare transformer and hybrid architectures. Scoring the loss on just the tokens that test a specific model ability surfaces key differences.
Second, specifically for hybrid models, the team found evidence of particular advantages on open-class tokens, which perhaps is related to the state-tracking capabilities of RNN layers.
The team is taking these findings into ongoing hybrid modeling work. They believe the best hybrid architectures will come from understanding, token by token, what each component of a model does well.
They hope studies like this help that understanding grow across the whole AI community.
Readers can read the full report, explore Olmo 3, try Olmo Hybrid, and dig into their associated open artifacts.