For creators and engineers, MiniMax M3 represents a shift from using AI as a chatbot to deploying it as a persistent, multimodal workforce. Released on June 1, 2026, the model natively handles image and video inputs while possessing the ability to operate a desktop computer. It is now accessible via the MiniMax API, the MiniMax Code platform, and the Token Plan, marking the latest evolution in their M-series following M2.7.
MiniMax positions M3 as a significant milestone: the first open-weight model to combine frontier-level coding performance, a massive 1M-token context window, and native multimodal input within a single architecture. The corresponding model weights and technical report are scheduled for release within ten days of this launch.
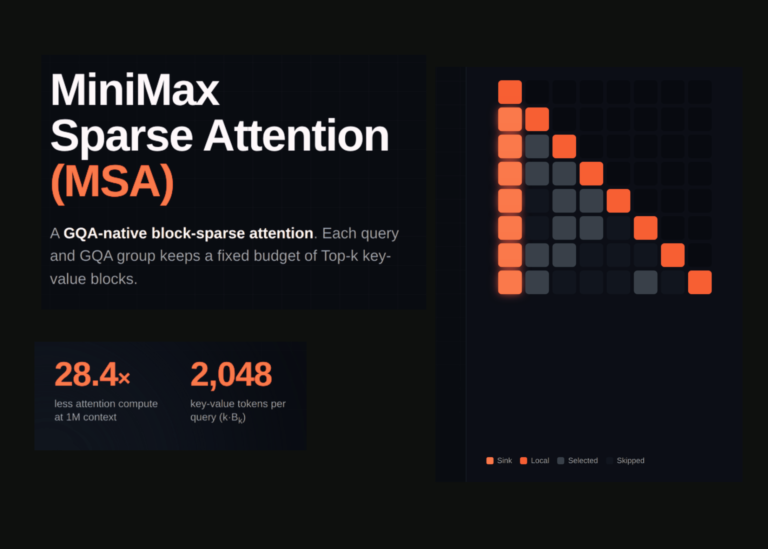
The MSA Architecture
The core innovation driving M3 is MSA (MiniMax Sparse Attention). While standard full attention suffers from quadratic computational complexity-where processing costs rise as the square of the sequence length-MSA is engineered to mitigate this bottleneck.
Unlike other sparse attention methods such as DSA or MoBA, MSA partitions the KV cache into blocks with greater precision, resulting in superior effective context coverage. At the operator level, it employs a “KV outer gather Q” mechanism. In this setup, KV blocks act as the outer loop to aggregate queries, ensuring each block is read only once with contiguous memory access.
MiniMax reports that this approach is over four times faster than open-source implementations like Flash-Sparse-Attention and flash-moba under M3’s specific head configuration. The efficiency gains are stark: at a 1M-token context, the per-token compute cost drops to one-twentieth of the previous M2 generation. This translates to a speedup of more than nine times in the prefill stage and over fifteen times in the decoding stage. Crucially, across multiple ablation studies, MSA matched the capabilities of full attention in the majority of tests.
Coding and Agentic Performance
M3 has been rigorously tested on coding and agentic benchmarks, with results reported by the MiniMax team. Several evaluations were conducted on internal infrastructure using specific scaffolding, while others drew from official leaderboards. Notably, SWE-Bench Verified and SWE-Bench Pro were tested on internal infrastructure using Claude Code scaffolding, aligning with official evaluation logic.
- SWE-Bench Pro: 59.0% (outperforms GPT-5.5 and Gemini 3.1 Pro; approaches Opus 4.7)
- Terminal-Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- KernelBench Hard: 28.8% (evaluated on NVIDIA Blackwell GPUs, CUDA capability sm_120)
- MCP Atlas: 74.2%
- Claw-Eval: Achieved the highest score among evaluated models (General Task Group, 161 tasks)
- SVG-Bench: Surpasses Opus 4.7
On OmniDocBench, a benchmark for multimodal document understanding, M3 scores higher than Gemini 3.1 Pro. In OSWorld-Verified, which tests computer usage across 361 samples with a maximum of 200 steps, the model achieved a 70.06% task completion rate.
To bridge the gap between isolated benchmarks and real-world workflows, MiniMax developed an interactive user simulator framework. This tool simulates multi-turn developer collaboration, encompassing requirement elaboration, solution discussion, feedback-based correction, continuous task switching, and multi-round project iteration.
Native Multimodality
Different from models that add vision capabilities post-training, MiniMax M3 underwent mixed-modality training from step zero. Text, images, and video are processed together from the outset. The team emphasises that interleaved data-sequences where text and images are naturally mixed-is more critical for performance than previously assumed. Following a complete rebuild of the data pipeline to support these formats, the training dataset was scaled to the order of 100 trillion tokens.
Real-World Task Demonstrations
MiniMax highlights three specific internal tasks to demonstrate M3’s autonomous capabilities:
Paper reproduction: The model was tasked with independently reproducing experiments from the ICLR 2025 Outstanding Paper Award-winning paper, Learning Dynamics of LLM Finetuning. Running autonomously for nearly 12 hours, M3 produced 18 commits and 23 experimental figures without human intervention. This required multimodal skills to interpret curves and formulas, a long context window to manage logs and papers simultaneously, and coding proficiency to execute the reproduction.
CUDA kernel optimization: Given only a task description, a benchmark script, and a non-functional Triton skeleton, M3 optimised an FP8 matrix multiplication kernel for NVIDIA Hopper architecture GPUs. Over 24 hours, it made 147 benchmark submissions and 1,959 tool calls. It progressed through baseline implementation, autotune configuration, bottleneck diagnosis, CUDA Graph integration, persistent kernel rewriting, and host-side scheduling optimisation. After six landmark rounds, it improved Hopper FP8 hardware peak utilisation from 7.6% to 71.3%, a 9.4× speedup. The optimal solution emerged on the 145th submission; MiniMax notes that most other models ceased making progress after the first 30 submissions.
PostTrainBench (autonomous model training): M3 was given four base models that had completed pretraining only. It autonomously executed a full cycle of data synthesis, training, evaluation, and iteration over 12 hours without human input. The goal was to acquire capabilities in mathematical reasoning (AIME2025), tool calling (BFCL), scientific knowledge reasoning (GPQA Main), arithmetic reasoning (GSM8K), and code generation (HumanEval). M3 scored 0.37, trailing Opus 4.7 (0.42) and GPT-5.5 (0.39) but outperforming the other tested base models.
Key takeaways
- MiniMax M3 is the first open-weight model to combine frontier coding, a 1M-token context window, and native multimodality in a single architecture.
- The proprietary MSA architecture delivers over 9× speedup in prefill and 15× in decoding at 1M tokens, reducing per-token compute to 1/20th of previous generations.
- Autonomous performance is demonstrated through complex tasks like reproducing research papers and optimising CUDA kernels, with a 9.4× speedup in hardware utilisation.