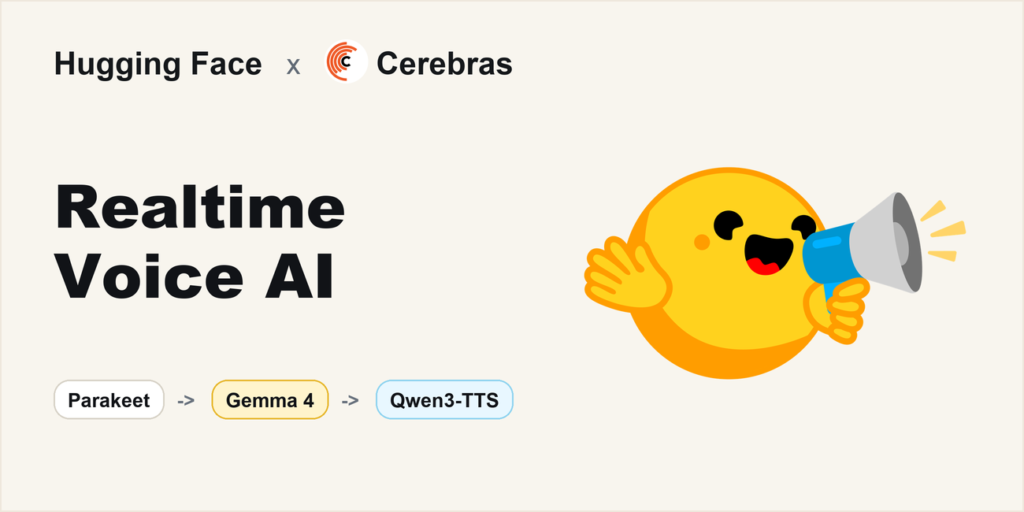
Voice chat over WebSocket against a HF speech-to-speech pipeline launched July 1, 2026.
Latency is the bottleneck
Developers have improved model quality, but user experience remains limited by response times. Hugging Face and Cerebras aim to fix this. They have paired an open, modular voice AI architecture with industry-leading inference speed.
The result is a speech-to-speech experience that feels more natural. Conversations flow with the responsiveness users expect from human interaction.
A modular stack
The demo is a real-time speech-to-speech pipeline. Each part of the system is modular, open, and replaceable. Developers can adapt the stack for different assistants, robots, products, or research projects.
This creates a fully open speech-to-speech loop:
- Speech input
- Speech recognition with Nvidia’s Parakeet
- Gemma 4 VLM inference on Cerebras
- Text-to-speech with Alibaba’s Qwen3TTS
- Spoken response
The architecture combines the strength of the open-source AI ecosystem. Cerebras provides fast inference. Google DeepMind’s Gemma 4 31B serves as the language model. Qwen handles text-to-speech. Every layer can be inspected, modified, and extended by developers.
Solving the P95 problem
Some production systems see a reasonable median latency while still experiencing frustrating multi-second delays at the P95. Those delays become even more noticeable when tool calls or multimodal steps require multiple turns.
Cerebras helps solve one of the most important bottlenecks in the stack: the language-model response time. By making inference dramatically faster and more stable, Cerebras allows the rest of the Hugging Face pipeline to shine.
That stability is especially important at the long tail. Many systems can deliver acceptable median response times, but occasional slow responses still make conversations feel unreliable.
Real-world deployment
This same Hugging Face speech-to-speech pipeline already powers Reachy Mini robots. More than 9,000 robots are in the wild. For robots, voice assistants, and embodied AI, responsiveness is not a cosmetic improvement. It is what makes the interaction feel alive.
The motivation to use Cerebras is therefore not simply cost reduction. It is low latency, predictable performance, and the ability to create real-time experiences that feel natural at scale.
What it means
The collaboration reflects a shared belief that the future of AI will be both open and performant. Open-source models, open infrastructure, and breakthrough inference speed together create a foundation for the next generation of conversational AI.
Developers can explore the demo and experiment with the code at the Hugging Face Space. The repository is available at huggingface/speech-to-speech.