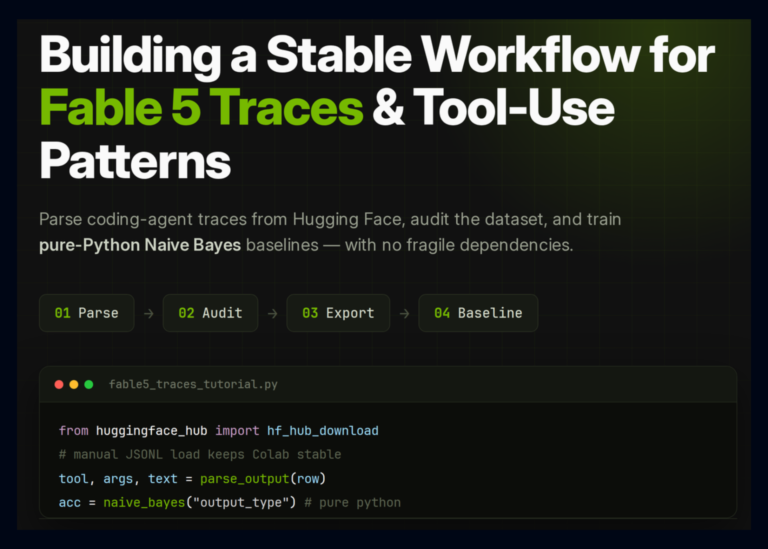
![How are you handling training data when public datasets don’t match your use case? [D]](https://ai-maestro.online/wp-content/uploads/2026/05/how-are-you-handling-training-data-when-public-datasets-don-1024x1024.jpg)
“`html
- The post discusses issues with publicly available datasets, which are often too generic or not aligned with specific use cases.
- It highlights common approaches like accepting degraded performance, spending time cleaning and scraping data, or using augmentation techniques. The author introduces their method of sourcing permissively licensed real-world data, curating it to fit a company’s needs, and augmenting as necessary.
-
– This post seeks feedback on whether the described approach is common or if other teams have found more effective workarounds.
– The author encourages others facing similar challenges to share their experiences.
– Approaches like using real-world data, curating it to fit specific needs, and augmenting as needed are presented as potential solutions to overcoming data limitations in AI projects.
“`
Source Read original →