
AI Research & Science
Peer-reviewed breakthroughs, university studies, and lab discoveries — explained in plain English. AI Maestro tracks the frontiers of machine learning research, neuroscience meets AI, and the science driving the next wave of intelligent systems.

Building the foundation for an autonomous enterprise
Woodside Energy in Western Australia has been using artificial intelligence since 2015. The company has spent a decade building predictive models and…

Top stories

LeRobot v0.6.0: Imagine, Evaluate, Improve
yesterday
AI search agents don’t fail at searching, they fail at asking the right questions when queries get ambiguous
2d ago
Anthropic Launches Claude Science Beta: A Multi-Agent AI Workbench for Reproducible Genomics, Proteomics, and Cheminformatics Pipelines
3d ago
NVIDIA HORIZON: A Hands-Free Agent that Evolves Git Worktrees and Hits 100% RTL Benchmark Completion
3d agoMore ai research & science

ig nobody is talking about the real reason most AI agents fail in the real world
we spend a lot of time in this community talking about capabilities. context windows,…
24 May 2026
Vision-capable LLMs vs. OCR for long-document (including charts, images, tables, etc.) QA [D]
I benchmarked vision-capable LLMs (the "just attach the PDF and let the model read…
24 May 2026
Vision-capable LLMs vs. OCR for long-document (including charts, images, tables, etc.) QA
I benchmarked vision-capable LLMs (the "just attach the PDF and let the model read…
24 May 2026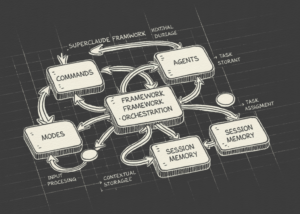
Build a SuperClaude Framework Workflow with Commands, Agents, Modes, and Session Memory
Key Takeaways We built an advanced workflow using the SuperClaude Framework, a structured layer…
23 May 2026
Is this the future of the economy?
“`html This Reddit post suggests a future where AI and robots perform all physical…
23 May 2026
Benchmarked Needle 26M vs Qwen3-0.6B on CPU function calling, 50 queries across 5 difficulty tiers. The 23x smaller model wins on accuracy and is 4.4x faster.
“`html Benchmarked Needle 26M vs Qwen3-0.6B on CPU Head-to-head benchmarking of two open-weight models:…
23 May 2026
Apex-Testing: real-world, real repos, agentic coding benchmark (Update)
“`html The Apex-Testing project has been updated with all recent models, based on 65-70…
23 May 2026
One of the world’s top law schools draws a hard line against AI in legal education
“`html One of the world’s top law schools, UC Berkeley Law, has taken a…
23 May 2026
Alibaba’s latest AI model ran autonomously for 35 hours to optimize code for its own custom chip
Alexandria’s latest AI model ran autonomously for 35 hours to optimize code for its…
23 May 2026