By AI Maestro
Automated news curation and AI-powered summaries from AI Maestro.

Claude vs GPT-4o vs Gemini vs Llama 3.3: LLM Comparison Guide 2026
Honest comparison of Claude, GPT-4o, Gemini, Llama 3.3, and Qwen 2.5 in 2026 —…
May 11, 2026
How to Run LLMs Locally with Ollama: The Complete 2026 Setup Guide
Step-by-step guide to running LLMs locally with Ollama in 2026 — hardware requirements, model…
May 11, 2026
Cloud vs Local vs API vs GPU Rental: The Honest LLM Deployment Guide (2026)
Cloud API, local Ollama, GPU rental, hybrid deployment: the complete guide to LLM infrastructure…
May 11, 2026
Understanding LLM Distillation Techniques
“`html Modern large language models are no longer trained solely on raw internet text.…
May 11, 2026
Quoting James Shore
**Editorial Brief** James Shore, a prominent figure in the tech industry, has emphasized the…
May 11, 2026
How to Build Technical Analysis and Backtesting Workflow with pandas-ta-classic, Strategy Signals, and Performance Metrics
How to Build a Technical Analysis and Trading Strategy Workflow with pandas-ta-classic In this…
May 11, 2026
Voice AI in India is hard — Wispr Flow is betting on it anyway
India’s Voice AI Challenge — Wispr Flow Sees Opportunity in India’s Digital Ecosystem Despite…
May 11, 2026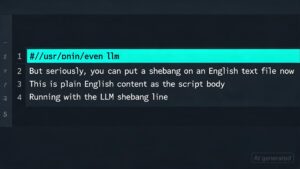
Using LLM in the shebang line of a script
Using LLM in the shebang line of a script TIL: Using LLM in the…
May 11, 2026Meta and Stanford Researchers Propose Fast Byte Latent Transformer That Reduces Inference Memory Bandwidth by Over 50% Without Tokenization
A team of researchers from Meta, Stanford University, and the University of Washington have…
May 11, 2026
Three things in AI to watch, according to a Nobel-winning economist
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get…
May 11, 2026