By AI Maestro
Automated news curation and AI-powered summaries from AI Maestro.

After 8 months of running everything local, ive accepted the productivity tools also have to be local
“`html After 8 Months of Running Everything Local After 8 Months of Running Everything…
May 12, 2026
Local LLM autocomplete + agentic coding on a single 16GB GPU + 64GB RAM
“`html Local LLM Autocomplete and Agentic Coding on a Single GPU Local LLM Autocomplete…
May 12, 2026
MTP+GGML_CUDA_ENABLE_UNIFIED_MEMORY=1 – llama.cpp
**Editorial Brief** The recent discussion on Reddit about the performance differences between `GGML_CUDA_ENABLE_UNIFIED_MEMORY=1` and…
May 12, 2026
Drastically improve prompt processing speed for –n-cpu-moe partially offloaded models
Bigger ubatch made gpt-oss-120b prompt processing much faster on my RTX 3090 I was…
May 12, 2026
“Tokenmaxxing” spreads at Amazon as employees game internal AI leaderboards
“Tokenmaxxing” is a phenomenon where employees use internal AI tools to artificially inflate their…
May 12, 2026
Amazon employees are “tokenmaxxing” due to pressure to use AI tools
**Editorial Brief** Amazon employees are reportedly using an internal AI tool called MeshClaw to…
May 12, 2026
Dessn raises $6M for its production focused design tool
Key Takeaways Dessn has raised $6 million in funding and is focused on helping…
May 12, 2026
Prompt alignment is an architectural ceiling: The Soap Bubble Problem and the biological precedent for Runtime Governance.
The Soap Bubble Problem The current approach to aligning agents relies on writing better…
May 12, 2026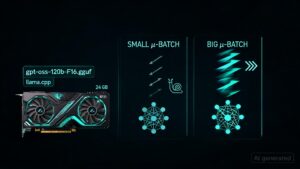
Drastically improve prompt processing speed for –n-cpu-moe partially offloaded models
Bigger ubatch made gpt-oss-120b prompt processing much faster on my RTX 3090 I was…
May 12, 2026
Thinking Machines Lab ships its first model and argues interactivity is what OpenAI gets wrong about voice
Thinking Machines Lab has released its first AI model, aiming to break away from…
May 12, 2026