**Editorial Brief**
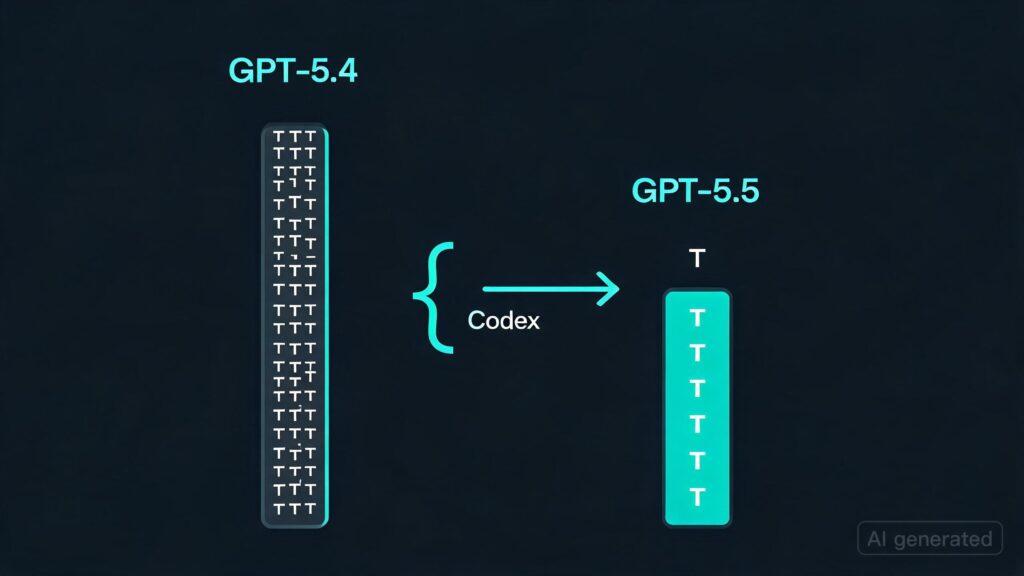
A recent post on r/singularity questions whether GPT-5.5 is more cost-efficient than its predecessor, GPT-5.4, by comparing token usage in a specific setup with Codex. The chart suggests that despite OpenAI‘s claims of improved efficiency, GPT-5.5 uses slightly more tokens (around 2.8M vs 2.5M) when paired with Codex.
This raises questions about whether this is due to differences in caching or pricing models rather than just a numerical difference. The comparison between GPT-5.5 and GPT-5.4 in the same setup seems more relevant, though it still shows an increase in token usage for GPT-5.5.
The post also highlights that Opus 4.7 uses fewer tokens, suggesting that this might be a more direct measure of efficiency. The comparison between different models like Cursor further emphasizes the importance of context and model specifics in evaluating cost-efficiency.
**Takeaways**
1. **Token Usage Variance**: GPT-5.5 appears to use slightly more tokens than expected when compared to its predecessor, highlighting potential discrepancies in how token counts are calculated or used.
2. **Context Matters**: Comparing models like GPT-5.4 and Opus 4.7 within the same framework reveals different performance metrics, suggesting that context is crucial for evaluating efficiency accurately.
3. **Model Specifics**: The comparison between different AI platforms (e.g., OpenAI vs. Cursor) underscores how specific model implementations can lead to varying token usage and overall cost-efficiency.